Note
Go to the end to download the full example code. or to run this example in your browser via Binder
BIDS dataset first and second level analysis¶
Full step-by-step example of fitting a GLM to perform a first and second level analysis in a BIDS dataset and visualizing the results. Details about the BIDS standard can be consulted at https://bids.neuroimaging.io/.
More specifically:
Download an fMRI BIDS dataset with two language conditions to contrast.
Extract first level model objects automatically from the BIDS dataset.
Fit a second level model on the fitted first level models. Notice that in this case the preprocessed bold images were already normalized to the same MNI space.
from nilearn import plotting
Fetch example BIDS dataset¶
We download a simplified BIDS dataset made available for illustrative purposes. It contains only the necessary information to run a statistical analysis using Nilearn. The raw data subject folders only contain bold.json and events.tsv files, while the derivatives folder includes the preprocessed files preproc.nii and the confounds.tsv files.
For more information see the dataset description.
from nilearn.datasets import fetch_language_localizer_demo_dataset
data = fetch_language_localizer_demo_dataset()
[fetch_language_localizer_demo_dataset] Dataset directory found: /home/runner/wo
rk/nilearn/nilearn/nilearn_data/fMRI-language-localizer-demo-dataset
Here is the location of the dataset on disk.
print(data.data_dir)
/home/runner/work/nilearn/nilearn/nilearn_data/fMRI-language-localizer-demo-dataset
Obtain automatically FirstLevelModel objects and fit arguments¶
From the dataset directory we automatically obtain the FirstLevelModel objects with their subject_id filled from the BIDS dataset. Moreover, we obtain for each model a dictionary with run_imgs, events and confounder regressors since in this case a confounds.tsv file is available in the BIDS dataset. To get the first level models we only have to specify the dataset directory and the task_label as specified in the file names.
from nilearn.glm.first_level import first_level_from_bids
task_label = "languagelocalizer"
(
models,
models_run_imgs,
models_events,
models_confounds,
) = first_level_from_bids(
data.data_dir,
task_label,
img_filters=[("desc", "preproc")],
n_jobs=2,
space_label="",
smoothing_fwhm=8,
)
/home/runner/work/nilearn/nilearn/examples/07_advanced/plot_bids_analysis.py:65: RuntimeWarning:
'StartTime' not found in file /home/runner/work/nilearn/nilearn/nilearn_data/fMRI-language-localizer-demo-dataset/derivatives/sub-01/func/sub-01_task-languagelocalizer_desc-preproc_bold.json.
/home/runner/work/nilearn/nilearn/examples/07_advanced/plot_bids_analysis.py:65: UserWarning:
'slice_time_ref' not provided and cannot be inferred from metadata.
It will be assumed that the slice timing reference is 0.0 percent of the repetition time.
If it is not the case it will need to be set manually in the generated list of models.
Quick sanity check on fit arguments¶
Additional checks or information extraction from pre-processed data can be made here.
We just expect one run_img per subject.
from pathlib import Path
print([Path(run).name for run in models_run_imgs[0]])
['sub-01_task-languagelocalizer_desc-preproc_bold.nii.gz']
The only confounds stored are regressors obtained from motion correction. As we can verify from the column headers of the confounds table corresponding to the only run_img present.
print(models_confounds[0][0].columns)
Index(['RotX', 'RotY', 'RotZ', 'X', 'Y', 'Z'], dtype='object')
During this acquisition the subject read blocks of sentences and consonant strings. So these are our only two conditions in events. We verify there are 12 blocks for each condition.
print(models_events[0][0]["trial_type"].value_counts())
trial_type
language 12
string 12
Name: count, dtype: int64
First level model estimation¶
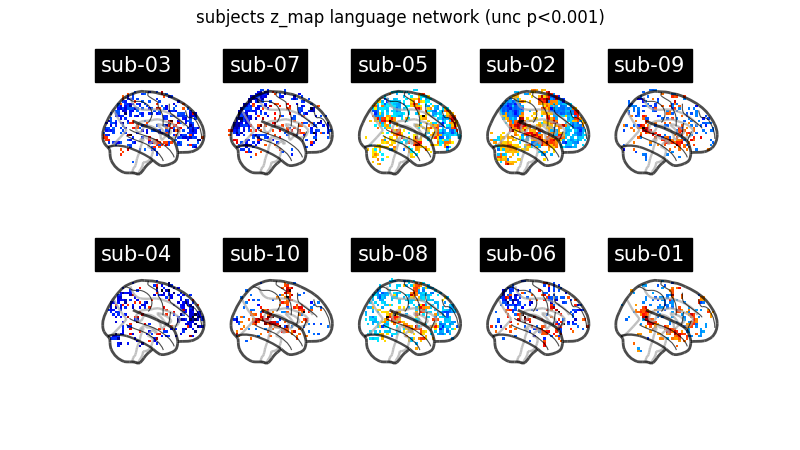
Now we simply fit each first level model and plot for each subject the contrast that reveals the language network (language - string). Notice that we can define a contrast using the names of the conditions specified in the events dataframe. Sum, subtraction and scalar multiplication are allowed.
Set the threshold as the z-variate with an uncorrected p-value of 0.001.
Prepare figure for concurrent plot of individual maps.
from math import ceil
import matplotlib.pyplot as plt
import numpy as np
ncols = 2
nrows = ceil(len(models) / ncols)
fig, axes = plt.subplots(nrows=nrows, ncols=ncols, figsize=(10, 12))
axes = np.atleast_2d(axes)
model_and_args = zip(
models, models_run_imgs, models_events, models_confounds, strict=False
)
for midx, (model, imgs, events, confounds) in enumerate(model_and_args):
# fit the GLM
model.fit(imgs, events, confounds)
# compute the contrast of interest
zmap = model.compute_contrast("language-string")
plotting.plot_glass_brain(
zmap,
threshold=p001_unc,
title=f"sub-{model.subject_label}",
axes=axes[int(midx / ncols), int(midx % ncols)],
plot_abs=False,
colorbar=True,
display_mode="x",
vmin=-12,
vmax=12,
)
fig.suptitle("subjects z_map language network (unc p<0.001)")
plotting.show()
Second level model estimation¶
We just have to provide the list of fitted FirstLevelModel objects to the SecondLevelModel object for estimation. We can do this because all subjects share a similar design matrix (same variables reflected in column names).
from nilearn.glm.second_level import SecondLevelModel
second_level_input = models
Note that we apply a smoothing of 8mm.
second_level_model = SecondLevelModel(smoothing_fwhm=8.0, n_jobs=2)
second_level_model = second_level_model.fit(second_level_input)
Computing contrasts at the second level is as simple as at the first level. Since we are not providing confounders we are performing a one-sample test at the second level with the images determined by the specified first level contrast.
zmap = second_level_model.compute_contrast(
first_level_contrast="language-string"
)
The group level contrast reveals a left lateralized fronto-temporal language network.
plotting.plot_glass_brain(
zmap,
threshold=p001_unc,
title="Group language network (unc p<0.001)",
plot_abs=False,
display_mode="x",
figure=plt.figure(figsize=(5, 4)),
)
plotting.show()

Generate and save the GLM report at the group level.
report_slm = second_level_model.generate_report(
contrasts="intercept",
first_level_contrast="language-string",
threshold=p001_unc,
display_mode="x",
)
/home/runner/work/nilearn/nilearn/examples/07_advanced/plot_bids_analysis.py:187: UserWarning:
'threshold=3.090232306167813' is not used with 'height_control='fpr''.
'threshold' is only used when 'height_control=None'.
'threshold' was set to 'None'.
View the GLM report at the group level.
Note
The generated report can be:
displayed in a Notebook,
opened in a browser using the
.open_in_browser()method,or saved to a file using the
.save_as_html(output_filepath)method.
SecondLevelModel
Implement the :term:`General Linear Model` for multiple subject :term:`fMRI` data.
WARNING
- 'threshold=3.090232306167813' is not used with 'height_control='fpr''. 'threshold' is only used when 'height_control=None'. 'threshold' was set to 'None'.
Description
Data were analyzed using Nilearn (version= 0.14.1; RRID:SCR_001362).
At the group level, a mass univariate analysis was performed with a linear regression at each voxel of the brain.
Input images were smoothed with gaussian kernel (full-width at half maximum=8.0 mm).
The following contrasts were computed :
- intercept
Model details
| Value | |
|---|---|
| Parameter | |
| smoothing_fwhm (mm) | 8.0 |
Design Matrix

Contrasts
.")
Mask

The mask includes 23640 voxels (23.1 %) of the image.
Statistical Maps
intercept

Cluster Table
| Height control | fpr |
|---|---|
| α | 0.001 |
| Threshold (computed) | 3.09 |
| Cluster size threshold (voxels) | 0 |
| Minimum distance (mm) | 8.0 |
| Cluster ID | X | Y | Z | Peak Stat | Cluster Size (mm3) |
|---|---|---|---|---|---|
| 1 | -57.5 | -48.5 | 13.5 | 4.43 | 6652 |
| 1a | -71.0 | -53.0 | 18.0 | 3.64 | |
| 2 | -62.0 | -8.0 | 49.5 | 4.32 | 1184 |
| 2a | -53.0 | -8.0 | 45.0 | 4.17 | |
| 2b | -48.5 | -3.5 | 54.0 | 3.16 | |
| 3 | -48.5 | -30.5 | -22.5 | 3.98 | 637 |
| 4 | 46.0 | 5.5 | -27.0 | 3.91 | 3371 |
| 4a | 50.5 | 23.5 | -27.0 | 3.80 | |
| 4b | 55.0 | 14.5 | -18.0 | 3.79 | |
| 5 | -71.0 | -17.0 | -4.5 | 3.89 | 9841 |
| 5a | -53.0 | -8.0 | -9.0 | 3.82 | |
| 5b | -66.5 | 1.0 | -4.5 | 3.82 | |
| 5c | -48.5 | 19.0 | -18.0 | 3.69 | |
| 6 | -39.5 | -3.5 | -40.5 | 3.60 | 455 |
| 7 | 50.5 | -12.5 | -9.0 | 3.51 | 364 |
| 8 | -48.5 | 14.5 | 18.0 | 3.43 | 364 |
| 9 | -75.5 | -35.0 | 4.5 | 3.32 | 91 |
| 10 | 32.5 | -17.0 | -27.0 | 3.26 | 91 |
| 11 | -44.0 | -17.0 | -31.5 | 3.13 | 182 |
About
- Date preprocessed:
Total running time of the script: (0 minutes 40.540 seconds)
Estimated memory usage: 400 MB