Note
Go to the end to download the full example code. or to run this example in your browser via Binder
Decoding with ANOVA + SVM: face vs house in the Haxby dataset¶
This example does a simple but efficient decoding on the Haxby dataset: using a feature selection, followed by an SVM.
import warnings
warnings.filterwarnings(
"ignore", message="The provided image has no sform in its header."
)
Retrieve the files of the Haxby dataset¶
from nilearn import datasets
# By default 2nd subject will be fetched
haxby_dataset = datasets.fetch_haxby()
func_img = haxby_dataset.func[0]
# print basic information on the dataset
print(f"Mask nifti image (3D) is located at: {haxby_dataset.mask}")
print(f"Functional nifti image (4D) is located at: {func_img}")
[fetch_haxby] Dataset directory found:
/home/runner/work/nilearn/nilearn/nilearn_data/haxby2001
Mask nifti image (3D) is located at: /home/runner/work/nilearn/nilearn/nilearn_data/haxby2001/mask.nii.gz
Functional nifti image (4D) is located at: /home/runner/work/nilearn/nilearn/nilearn_data/haxby2001/subj2/bold.nii.gz
Load the behavioral data¶
import pandas as pd
# Load target information as string and give a numerical identifier to each
behavioral = pd.read_csv(haxby_dataset.session_target[0], sep=" ")
conditions = behavioral["labels"]
# Restrict the analysis to faces and places
from nilearn.image import index_img
condition_mask = behavioral["labels"].isin(["face", "house"])
conditions = conditions[condition_mask]
func_img = index_img(func_img, condition_mask)
# Confirm that we now have 2 conditions
print(conditions.unique())
# The number of the run is stored in the CSV file giving the behavioral data.
# We have to apply our run mask, to select only faces and houses.
run_label = behavioral["chunks"][condition_mask]
['face' 'house']
ANOVA pipeline with Decoder object¶
Nilearn Decoder object aims to provide smooth user experience by acting as a pipeline of several tasks: preprocessing with NiftiMasker, reducing dimension by selecting only relevant features with ANOVA – a classical univariate feature selection based on F-test, and then decoding with different types of estimators (in this example is Support Vector Machine with a linear kernel) on nested cross-validation.
from nilearn.decoding import Decoder
# Here we select the best 500 voxels of each fold of the cross-validation
screening_n_features = 500
screening_percentile = None
mask_img = haxby_dataset.mask
decoder = Decoder(
estimator="svc",
mask=mask_img,
smoothing_fwhm=4,
screening_percentile=screening_percentile,
screening_n_features=screening_n_features,
scoring="accuracy",
verbose=2,
)
Fit the decoder and predict¶
\[Decoder.fit] Loading mask from
'/home/runner/work/nilearn/nilearn/nilearn_data/haxby2001/mask.nii.gz'
\[Decoder.fit] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f2ae104eb30>
\[Decoder.fit] Resampling mask
\[Decoder.fit] Finished fit
\[Decoder.fit] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f2ae104eb30>
\[Decoder.fit] Smoothing images
\[Decoder.fit] Extracting region signals
\[Decoder.fit] Cleaning extracted signals
\[Decoder.fit] The decoding model will be trained on 39912 features.
\[Decoder.fit] The decoding model will be trained on 39912 features.
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 5697 13114 15883 29793 31019] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
\[Decoder.fit] Selection kept 500 features.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.1s remaining: 0.0s
\[Decoder.fit] Selection kept 500 features.
[Parallel(n_jobs=1)]: Done 2 out of 2 | elapsed: 0.2s remaining: 0.0s
\[Decoder.fit] Selection kept 500 features.
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 0.4s remaining: 0.0s
\[Decoder.fit] Selection kept 500 features.
\[Decoder.fit] Selection kept 500 features.
\[Decoder.fit] Selection kept 500 features.
\[Decoder.fit] Selection kept 500 features.
\[Decoder.fit] Selection kept 500 features.
\[Decoder.fit] Selection kept 500 features.
\[Decoder.fit] Selection kept 500 features.
[Parallel(n_jobs=1)]: Done 10 out of 10 | elapsed: 1.2s finished
\[Decoder.fit] Computing image from signals
\[Decoder.fit] Computing image from signals
\[Decoder.fit] Computing image from signals
\[Decoder.fit] Computing image from signals
\[Decoder.predict] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f2ae104eb30>
\[Decoder.predict] Smoothing images
\[Decoder.predict] Extracting region signals
\[Decoder.predict] Cleaning extracted signals
Obtain prediction scores via cross validation¶
Define the cross-validation scheme used for validation. Here we use a LeaveOneGroupOut cross-validation on the run group which corresponds to a leave a run out scheme, then pass the cross-validator object to the cv parameter of decoder.leave-one-session-out. For more details please take a look at: An introduction tutorial to fMRI decoding.
from sklearn.model_selection import LeaveOneGroupOut
cv = LeaveOneGroupOut()
decoder = Decoder(
estimator="svc",
mask=mask_img,
screening_percentile=screening_percentile,
screening_n_features=screening_n_features,
scoring="accuracy",
cv=cv,
verbose=2,
)
# Compute the prediction accuracy for the different folds (i.e. run)
decoder.fit(func_img, conditions, groups=run_label)
# Print the CV scores
print(decoder.cv_scores_["face"])
\[Decoder.fit] Loading mask from
'/home/runner/work/nilearn/nilearn/nilearn_data/haxby2001/mask.nii.gz'
\[Decoder.fit] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f2ae104eb30>
\[Decoder.fit] Resampling mask
\[Decoder.fit] Finished fit
\[Decoder.fit] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f2ae104eb30>
\[Decoder.fit] Extracting region signals
\[Decoder.fit] Cleaning extracted signals
\[Decoder.fit] The decoding model will be trained on 39912 features.
\[Decoder.fit] The decoding model will be trained on 39912 features.
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [15883 28394 29793] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
\[Decoder.fit] Selection kept 500 features.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.1s remaining: 0.0s
\[Decoder.fit] Selection kept 500 features.
[Parallel(n_jobs=1)]: Done 2 out of 2 | elapsed: 0.2s remaining: 0.0s
\[Decoder.fit] Selection kept 500 features.
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 0.3s remaining: 0.0s
\[Decoder.fit] Selection kept 500 features.
\[Decoder.fit] Selection kept 500 features.
\[Decoder.fit] Selection kept 500 features.
\[Decoder.fit] Selection kept 500 features.
\[Decoder.fit] Selection kept 500 features.
\[Decoder.fit] Selection kept 500 features.
\[Decoder.fit] Selection kept 500 features.
\[Decoder.fit] Selection kept 500 features.
\[Decoder.fit] Selection kept 500 features.
[Parallel(n_jobs=1)]: Done 12 out of 12 | elapsed: 1.2s finished
\[Decoder.fit] Computing image from signals
\[Decoder.fit] Computing image from signals
\[Decoder.fit] Computing image from signals
\[Decoder.fit] Computing image from signals
[0.8333333333333334, 0.9444444444444444, 0.9444444444444444, 0.8333333333333334, 0.9444444444444444, 1.0, 0.8888888888888888, 1.0, 0.5, 0.8888888888888888, 1.0, 1.0]
Visualize the results¶
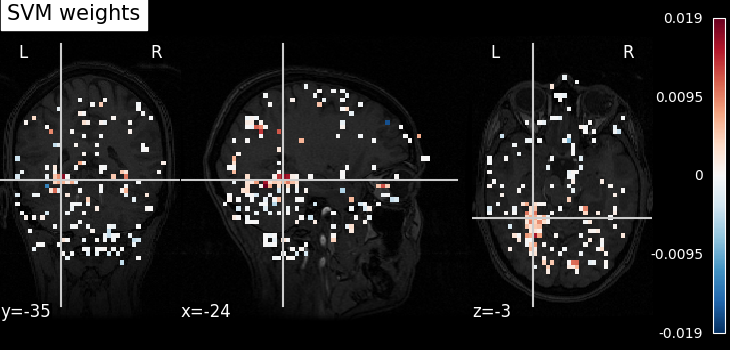
Look at the SVC’s discriminating weights using
plot_stat_map
weight_img = decoder.coef_img_["face"]
from nilearn.plotting import plot_stat_map, show
plot_stat_map(weight_img, bg_img=haxby_dataset.anat[0], title="SVM weights")
show()
Or we can plot the weights using view_img as a
dynamic html viewer
from nilearn.plotting import view_img
view_img(weight_img, bg_img=haxby_dataset.anat[0], title="SVM weights", dim=-1)
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/numpy/core/fromnumeric.py:771: UserWarning:
Warning: 'partition' will ignore the 'mask' of the MaskedArray.
/home/runner/work/nilearn/nilearn/examples/02_decoding/plot_haxby_anova_svm.py:130: UserWarning:
Casting data from int16 to float32