Note
Go to the end to download the full example code. or to run this example in your browser via Binder
Beta-Series Modeling for Task-Based Functional Connectivity and Decoding¶
This example shows how to run beta series GLM models, which are a common modeling approach for a variety of analyses of task-based fMRI data with an event-related task design, including functional connectivity, decoding, and representational similarity analysis.
Beta series models fit trial-wise conditions, which allow users to create “time series” of these trial-wise maps, which can be substituted for the typical time series used in resting-state functional connectivity analyses. Generally, these models are most useful for event-related task designs, while other modeling approaches, such as psychophysiological interactions (PPIs), tend to perform better in block designs, depending on the type of analysis. See Cisler et al.[1] for more information about this, in the context of functional connectivity analyses.
Two of the most well-known beta series modeling methods are Least Squares- All (LSA) (Rissman et al.[2]) and Least Squares- Separate (LSS) (Mumford et al.[3], Turner et al.[4]). In LSA, a single GLM is run, in which each trial of each condition of interest is separated out into its own condition within the design matrix. In LSS, each trial of each condition of interest has its own GLM, in which the targeted trial receives its own column within the design matrix, but everything else remains the same as the standard model. Trials are then looped across, and many GLMs are fitted, with the Parameter Estimate map extracted from each GLM to build the LSS beta series.
Prepare data and analysis parameters¶
Download data in BIDS format and event information for one subject,
and create a standard FirstLevelModel.
For more information see the dataset description.
from nilearn.datasets import fetch_language_localizer_demo_dataset
from nilearn.glm.first_level import FirstLevelModel, first_level_from_bids
from nilearn.plotting import plot_design_matrix, plot_stat_map, show
data = fetch_language_localizer_demo_dataset()
models, models_run_imgs, events_dfs, models_confounds = first_level_from_bids(
dataset_path=data.data_dir,
task_label="languagelocalizer",
space_label="",
sub_labels=["01"],
img_filters=[("desc", "preproc")],
n_jobs=2,
)
# Grab the first subject's model, functional file, and events DataFrame
standard_glm = models[0]
fmri_file = models_run_imgs[0][0]
events_df = events_dfs[0][0]
# We will use first_level_from_bids's parameters for the other models
glm_parameters = standard_glm.get_params()
# We need to override one parameter (signal_scaling)
# with the value of scaling_axis
glm_parameters["signal_scaling"] = standard_glm.signal_scaling
[fetch_language_localizer_demo_dataset] Dataset directory found: /home/runner/wo
rk/nilearn/nilearn/nilearn_data/fMRI-language-localizer-demo-dataset
/home/runner/work/nilearn/nilearn/examples/07_advanced/plot_beta_series.py:76: RuntimeWarning:
'StartTime' not found in file /home/runner/work/nilearn/nilearn/nilearn_data/fMRI-language-localizer-demo-dataset/derivatives/sub-01/func/sub-01_task-languagelocalizer_desc-preproc_bold.json.
/home/runner/work/nilearn/nilearn/examples/07_advanced/plot_beta_series.py:76: UserWarning:
'slice_time_ref' not provided and cannot be inferred from metadata.
It will be assumed that the slice timing reference is 0.0 percent of the repetition time.
If it is not the case it will need to be set manually in the generated list of models.
Define the standard model¶
Here, we create a basic GLM for this run, which we can use to
highlight differences between the standard modeling approach and beta series
models.
We will just use the one created by
first_level_from_bids.
import matplotlib.pyplot as plt
print("Fit model")
standard_glm.fit(fmri_file, events_df)
# The standard design matrix has one column for each condition, along with
# columns for the confound regressors and drifts
fig, ax = plt.subplots(figsize=(5, 10))
plot_design_matrix(standard_glm.design_matrices_[0], axes=ax)
show()
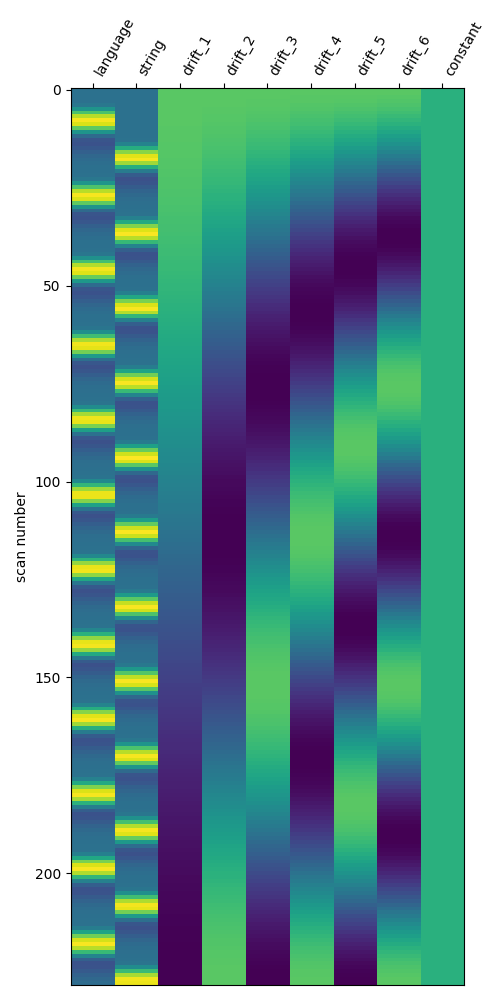
Fit model
Define the LSA model¶
We will now create a Least Squares All (LSA) model. This involves a simple transformation, where each trial of interest receives its own unique trial type. It’s important to ensure that the original trial types can be inferred from the updated trial-wise trial types, in order to collect the resulting beta maps into condition-wise beta series.
print("Define and fit LSA")
# Transform the DataFrame for LSA
lsa_events_df = events_df.copy()
conditions = lsa_events_df["trial_type"].unique()
condition_counter = dict.fromkeys(conditions, 0)
for i_trial, trial in lsa_events_df.iterrows():
trial_condition = trial["trial_type"]
condition_counter[trial_condition] += 1
# We use a unique delimiter here (``__``) that shouldn't be in the
# original condition names
trial_name = f"{trial_condition}__{condition_counter[trial_condition]:03d}"
lsa_events_df.loc[i_trial, "trial_type"] = trial_name
lsa_glm = FirstLevelModel(**glm_parameters)
lsa_glm.fit(fmri_file, lsa_events_df)
fig, ax = plt.subplots(figsize=(10, 10))
plot_design_matrix(lsa_glm.design_matrices_[0], axes=ax)
show()
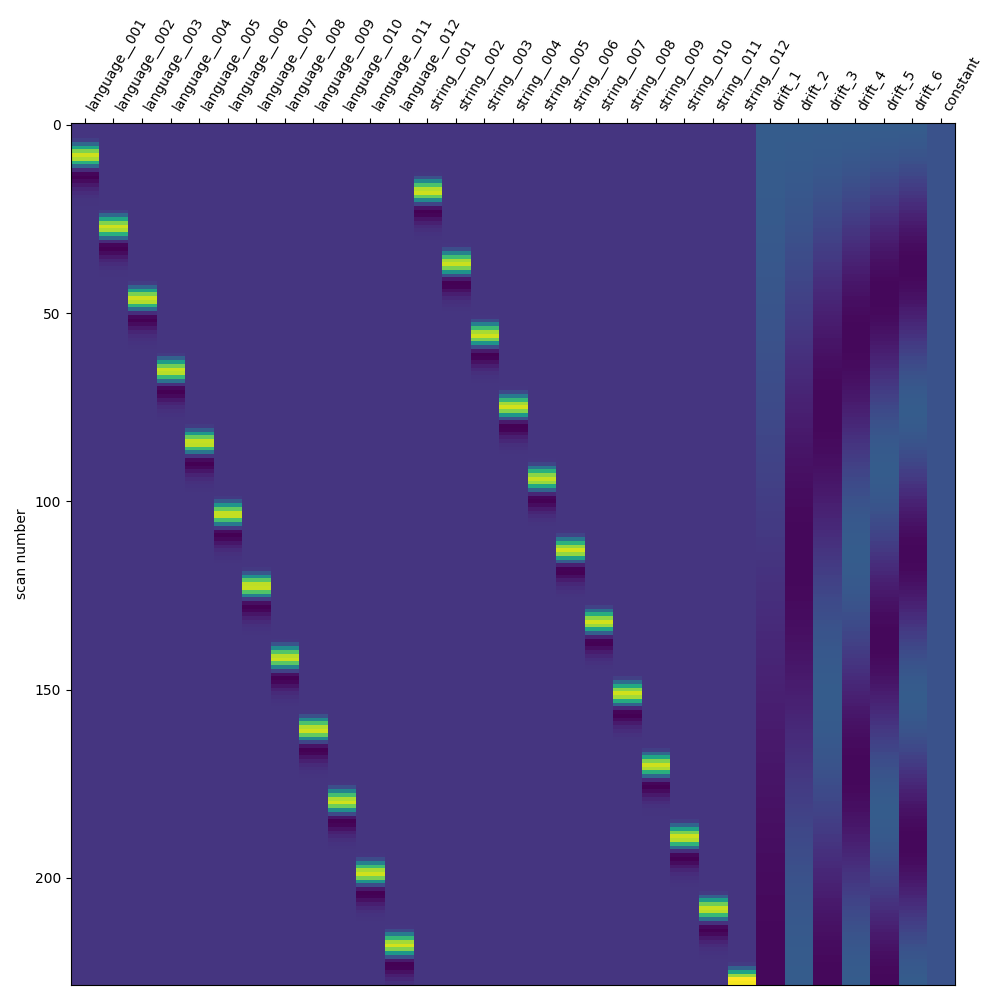
Define and fit LSA
Aggregate beta maps from the LSA model based on condition¶
Collect the Parameter Estimate maps
from nilearn.image import concat_imgs
lsa_beta_maps = {cond: [] for cond in events_df["trial_type"].unique()}
trialwise_conditions = lsa_events_df["trial_type"].unique()
for condition in trialwise_conditions:
beta_map = lsa_glm.compute_contrast(condition, output_type="effect_size")
# Drop the trial number from the condition name to get the original name
condition_name = condition.split("__")[0]
lsa_beta_maps[condition_name].append(beta_map)
# We can concatenate the lists of 3D maps into a single 4D beta series for
# each condition, if we want
lsa_beta_maps = {
name: concat_imgs(maps) for name, maps in lsa_beta_maps.items()
}
Define the LSS models¶
We will now create a separate Least Squares Separate (LSS) model for each trial of interest. The transformation is much like the LSA approach, except that we only relabel one trial in the DataFrame. We loop through the trials, create a version of the DataFrame where the targeted trial has a unique trial type, fit the model to that DataFrame, and finally collect the targeted trial’s beta map for the beta series.
print("Define and fit LSS")
def lss_transformer(events_df, row_number):
"""Label one trial for one LSS model.
Parameters
----------
df : pandas.DataFrame
BIDS-compliant events file information.
row_number : int
Row number in the DataFrame.
This indexes the trial that will be isolated.
Returns
-------
df : pandas.DataFrame
Update events information, with the select trial's trial type isolated.
trial_name : str
Name of the isolated trial's trial type.
"""
events_df = events_df.copy()
# Determine which number trial it is *within the condition*
trial_condition = events_df.loc[row_number, "trial_type"]
trial_type_series = events_df["trial_type"]
trial_type_series = trial_type_series.loc[
trial_type_series == trial_condition
]
trial_type_list = trial_type_series.index.tolist()
trial_number = trial_type_list.index(row_number)
# We use a unique delimiter here (``__``) that shouldn't be in the
# original condition names.
# Technically, all you need is for the requested trial to have a unique
# 'trial_type' *within* the dataframe, rather than across models.
# However, we may want to have meaningful 'trial_type's (e.g., 'Left_001')
# across models, so that you could track individual trials across models.
trial_name = f"{trial_condition}__{trial_number:03d}"
events_df.loc[row_number, "trial_type"] = trial_name
return events_df, trial_name
# Loop through the trials of interest and transform the DataFrame for LSS
lss_beta_maps = {cond: [] for cond in events_df["trial_type"].unique()}
lss_design_matrices = []
for i_trial in range(events_df.shape[0]):
lss_events_df, trial_condition = lss_transformer(events_df, i_trial)
# Compute and collect beta maps
lss_glm = FirstLevelModel(**glm_parameters)
lss_glm.fit(fmri_file, lss_events_df)
# We will save the design matrices across trials to show them later
lss_design_matrices.append(lss_glm.design_matrices_[0])
beta_map = lss_glm.compute_contrast(
trial_condition,
output_type="effect_size",
)
# Drop the trial number from the condition name to get the original name
condition_name = trial_condition.split("__")[0]
lss_beta_maps[condition_name].append(beta_map)
# We can concatenate the lists of 3D maps into a single 4D beta series for
# each condition, if we want
lss_beta_maps = {
name: concat_imgs(maps) for name, maps in lss_beta_maps.items()
}
Define and fit LSS
Show the design matrices for the first few trials¶
fig, axes = plt.subplots(ncols=3, figsize=(20, 10))
for i_trial in range(3):
plot_design_matrix(
lss_design_matrices[i_trial],
axes=axes[i_trial],
)
axes[i_trial].set_title(f"Trial {i_trial + 1}")
show()
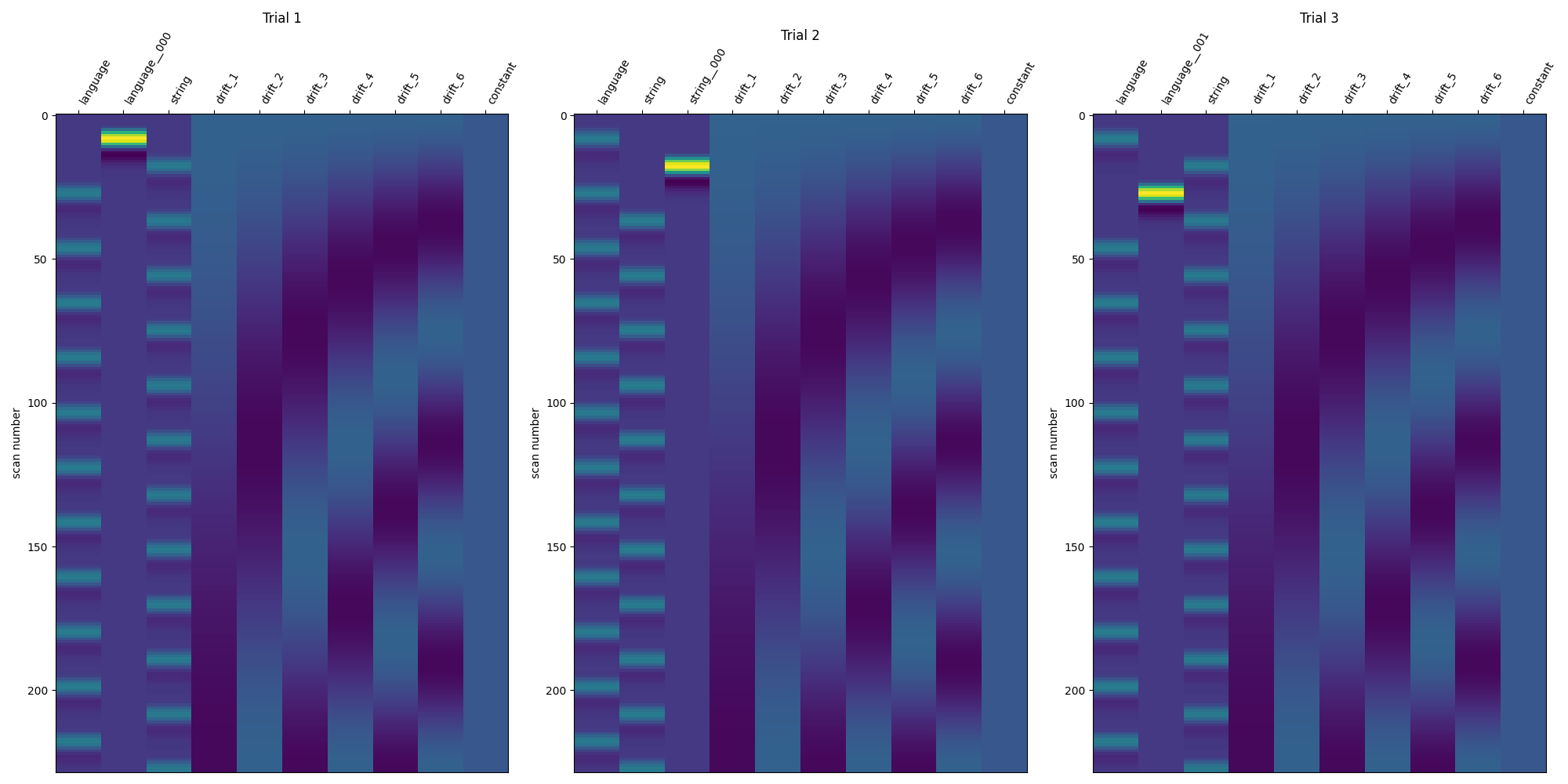
Compare the three modeling approaches¶
print("Compare models")
DM_TITLES = ["Standard GLM", "LSA Model", "LSS Model (Trial 1)"]
DESIGN_MATRICES = [
standard_glm.design_matrices_[0],
lsa_glm.design_matrices_[0],
lss_design_matrices[0],
]
fig, axes = plt.subplots(
ncols=3,
figsize=(20, 10),
gridspec_kw={"width_ratios": [1, 2, 1]},
)
for i_ax, _ in enumerate(axes):
plot_design_matrix(DESIGN_MATRICES[i_ax], axes=axes[i_ax])
axes[i_ax].set_title(DM_TITLES[i_ax])
show()
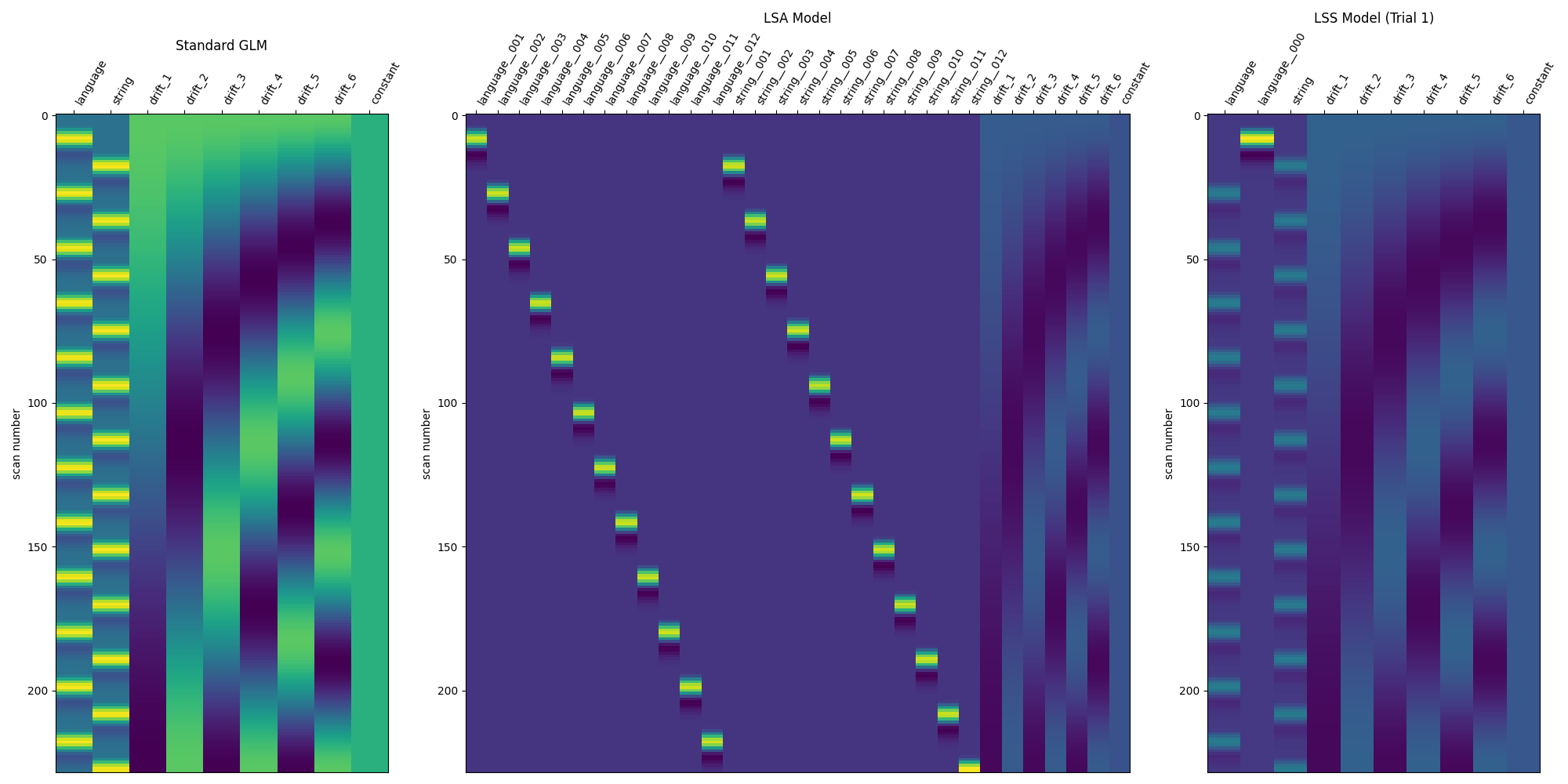
Compare models
Applications of beta series¶
Beta series can be used much like resting-state data, though generally with vastly reduced degrees of freedom than a typical resting-state run, given that the number of trials should always be less than the number of volumes in a functional MRI run.
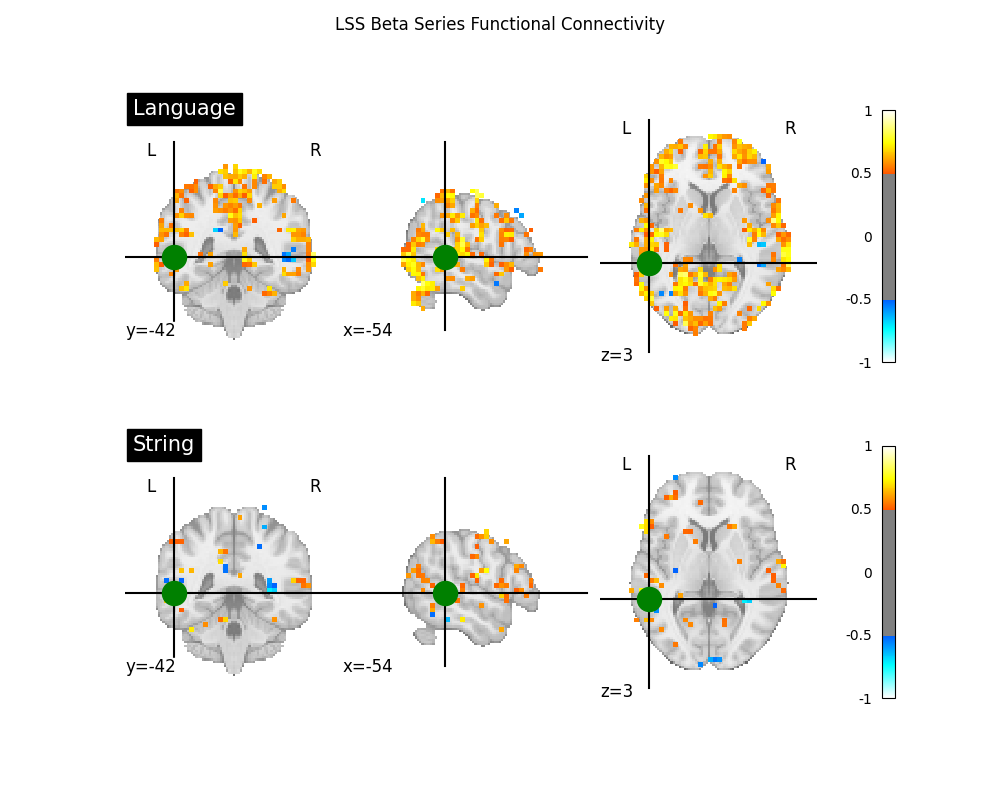
Two common applications of beta series are to functional connectivity and decoding analyses. For an example of a beta series applied to decoding, see Decoding of a dataset after GLM fit for signal extraction. Here, we show how the beta series can be applied to functional connectivity analysis. In the following section, we perform a quick task-based functional connectivity analysis of each of the two task conditions (‘language’ and ‘string’), using the LSS beta series. This section is based on Producing single subject maps of seed-to-voxel correlation, which goes into more detail about seed-to-voxel functional connectivity analyses.
import numpy as np
from nilearn.maskers import NiftiMasker, NiftiSpheresMasker
print("Apply beta series")
# Coordinate taken from Neurosynth's 'language' meta-analysis
coords = [(-54, -42, 3)]
# Initialize maskers for the seed and the rest of the brain
seed_masker = NiftiSpheresMasker(
coords,
radius=8,
detrend=True,
memory="nilearn_cache",
memory_level=1,
verbose=1,
)
brain_masker = NiftiMasker(
smoothing_fwhm=6,
detrend=True,
memory="nilearn_cache",
memory_level=1,
verbose=1,
)
# Perform the seed-to-voxel correlation for the LSS 'language' beta series
lang_seed_beta_series = seed_masker.fit_transform(lss_beta_maps["language"])
lang_beta_series = brain_masker.fit_transform(lss_beta_maps["language"])
lang_corrs = (
np.dot(
lang_beta_series.T,
lang_seed_beta_series,
)
/ lang_seed_beta_series.shape[0]
)
language_connectivity_img = brain_masker.inverse_transform(lang_corrs.T)
# Same but now for the LSS 'string' beta series
string_seed_beta_series = seed_masker.fit_transform(lss_beta_maps["string"])
string_beta_series = brain_masker.fit_transform(lss_beta_maps["string"])
string_corrs = (
np.dot(
string_beta_series.T,
string_seed_beta_series,
)
/ string_seed_beta_series.shape[0]
)
string_connectivity_img = brain_masker.inverse_transform(string_corrs.T)
# Show both correlation maps
fig, axes = plt.subplots(figsize=(10, 8), nrows=2)
display = plot_stat_map(
language_connectivity_img,
threshold=0.5,
vmax=1,
cut_coords=coords[0],
title="Language",
figure=fig,
axes=axes[0],
)
display.add_markers(
marker_coords=coords,
marker_color="g",
marker_size=300,
)
display = plot_stat_map(
string_connectivity_img,
threshold=0.5,
vmax=1,
cut_coords=coords[0],
title="String",
figure=fig,
axes=axes[1],
)
display.add_markers(
marker_coords=coords,
marker_color="g",
marker_size=300,
)
fig.suptitle("LSS Beta Series Functional Connectivity")
show()
Apply beta series
\[NiftiSpheresMasker.wrapped] Finished fit
/home/runner/work/nilearn/nilearn/examples/07_advanced/plot_beta_series.py:337: FutureWarning:
boolean values for 'standardize' will be deprecated in nilearn 0.15.0.
Use 'zscore_sample' instead of 'True' or use 'None' instead of 'False'.
________________________________________________________________________________
[Memory] Calling nilearn.maskers.base_masker.filter_and_extract...
filter_and_extract(<nibabel.nifti1.Nifti1Image object at 0x7f10c3de37c0>, <nilearn.maskers.nifti_spheres_masker._ExtractionFunctor object at 0x7f1096778280>,
{ 'allow_overlap': False,
'clean_args': None,
'clean_kwargs': {},
'detrend': True,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'mask_img': None,
'radius': 8,
'reports': True,
'seeds': [(-54, -42, 3)],
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None}, confounds=None, sample_mask=None, dtype=None, sklearn_output_config=None, memory=Memory(location=nilearn_cache/joblib), memory_level=1, verbose=1)
\[NiftiSpheresMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image
object at 0x7f10c3de37c0>
\[NiftiSpheresMasker.wrapped] Extracting region signals
\[NiftiSpheresMasker.wrapped] Cleaning extracted signals
/home/runner/work/nilearn/nilearn/examples/07_advanced/plot_beta_series.py:337: FutureWarning:
boolean values for 'standardize' will be deprecated in nilearn 0.15.0.
Use 'zscore_sample' instead of 'True' or use 'None' instead of 'False'.
_______________________________________________filter_and_extract - 1.3s, 0.0min
\[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f10c3de37c0>
\[NiftiMasker.wrapped] Computing mask
________________________________________________________________________________
[Memory] Calling nilearn.masking.compute_background_mask...
compute_background_mask(<nibabel.nifti1.Nifti1Image object at 0x7f10c3de37c0>, verbose=0)
__________________________________________compute_background_mask - 0.0s, 0.0min
\[NiftiMasker.wrapped] Resampling mask
________________________________________________________________________________
[Memory] Calling nilearn.image.resampling.resample_img...
resample_img(<nibabel.nifti1.Nifti1Image object at 0x7f109677a320>, target_affine=None, target_shape=None, copy=False, interpolation='nearest')
_____________________________________________________resample_img - 0.0s, 0.0min
\[NiftiMasker.wrapped] Finished fit
/home/runner/work/nilearn/nilearn/examples/07_advanced/plot_beta_series.py:338: FutureWarning:
boolean values for 'standardize' will be deprecated in nilearn 0.15.0.
Use 'zscore_sample' instead of 'True' or use 'None' instead of 'False'.
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f10c3de37c0>, <nibabel.nifti1.Nifti1Image object at 0x7f109677a320>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': True,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': 6,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, sklearn_output_config=None)
\[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f10c3de37c0>
\[NiftiMasker.wrapped] Smoothing images
\[NiftiMasker.wrapped] Extracting region signals
\[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.1s, 0.0min
\[NiftiMasker.inverse_transform] Computing image from signals
________________________________________________________________________________
[Memory] Calling nilearn.masking.unmask...
unmask(array([[ 0.00839 , ..., -0.007952]], dtype=float32), <nibabel.nifti1.Nifti1Image object at 0x7f109677a320>)
___________________________________________________________unmask - 0.0s, 0.0min
\[NiftiSpheresMasker.wrapped] Finished fit
/home/runner/work/nilearn/nilearn/examples/07_advanced/plot_beta_series.py:349: FutureWarning:
boolean values for 'standardize' will be deprecated in nilearn 0.15.0.
Use 'zscore_sample' instead of 'True' or use 'None' instead of 'False'.
________________________________________________________________________________
[Memory] Calling nilearn.maskers.base_masker.filter_and_extract...
filter_and_extract(<nibabel.nifti1.Nifti1Image object at 0x7f10dedfe350>, <nilearn.maskers.nifti_spheres_masker._ExtractionFunctor object at 0x7f109677b610>,
{ 'allow_overlap': False,
'clean_args': None,
'clean_kwargs': {},
'detrend': True,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'mask_img': None,
'radius': 8,
'reports': True,
'seeds': [(-54, -42, 3)],
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None}, confounds=None, sample_mask=None, dtype=None, sklearn_output_config=None, memory=Memory(location=nilearn_cache/joblib), memory_level=1, verbose=1)
\[NiftiSpheresMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image
object at 0x7f10dedfe350>
\[NiftiSpheresMasker.wrapped] Extracting region signals
\[NiftiSpheresMasker.wrapped] Cleaning extracted signals
/home/runner/work/nilearn/nilearn/examples/07_advanced/plot_beta_series.py:349: FutureWarning:
boolean values for 'standardize' will be deprecated in nilearn 0.15.0.
Use 'zscore_sample' instead of 'True' or use 'None' instead of 'False'.
_______________________________________________filter_and_extract - 0.9s, 0.0min
\[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f10dedfe350>
\[NiftiMasker.wrapped] Computing mask
________________________________________________________________________________
[Memory] Calling nilearn.masking.compute_background_mask...
compute_background_mask(<nibabel.nifti1.Nifti1Image object at 0x7f10dedfe350>, verbose=0)
__________________________________________compute_background_mask - 0.0s, 0.0min
\[NiftiMasker.wrapped] Resampling mask
________________________________________________________________________________
[Memory] Calling nilearn.image.resampling.resample_img...
resample_img(<nibabel.nifti1.Nifti1Image object at 0x7f10efc3c460>, target_affine=None, target_shape=None, copy=False, interpolation='nearest')
_____________________________________________________resample_img - 0.0s, 0.0min
\[NiftiMasker.wrapped] Finished fit
/home/runner/work/nilearn/nilearn/examples/07_advanced/plot_beta_series.py:350: FutureWarning:
boolean values for 'standardize' will be deprecated in nilearn 0.15.0.
Use 'zscore_sample' instead of 'True' or use 'None' instead of 'False'.
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f10dedfe350>, <nibabel.nifti1.Nifti1Image object at 0x7f10efc3c460>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': True,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': 6,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, sklearn_output_config=None)
\[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f10dedfe350>
\[NiftiMasker.wrapped] Smoothing images
\[NiftiMasker.wrapped] Extracting region signals
\[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.1s, 0.0min
\[NiftiMasker.inverse_transform] Computing image from signals
________________________________________________________________________________
[Memory] Calling nilearn.masking.unmask...
unmask(array([[ 0.015765, ..., -0.016087]], dtype=float32), <nibabel.nifti1.Nifti1Image object at 0x7f10efc3c460>)
___________________________________________________________unmask - 0.0s, 0.0min
/home/runner/work/nilearn/nilearn/examples/07_advanced/plot_beta_series.py:363: UserWarning:
empty mask
/home/runner/work/nilearn/nilearn/examples/07_advanced/plot_beta_series.py:378: UserWarning:
empty mask
References¶
Total running time of the script: (1 minutes 16.771 seconds)
Estimated memory usage: 310 MB