Note
Go to the end to download the full example code. or to run this example in your browser via Binder
Massively univariate analysis of a motor task from the Localizer dataset¶
This example shows the results obtained in a massively univariate analysis performed at the inter-subject level with various methods. We use the [left button press (auditory cue)] task from the Localizer dataset and seek association between the contrast values and a variate that measures the speed of pseudo-word reading. No confounding variate is included in the model.
A standard ANOVA is performed. Data smoothed at 5 voxels FWHM are used.
A permuted Ordinary Least Squares algorithm is run at each voxel. Data smoothed at 5 voxels FWHM are used.
from nilearn._utils.helpers import check_matplotlib
check_matplotlib()
import numpy as np
from nilearn import datasets
from nilearn.maskers import NiftiMasker
from nilearn.mass_univariate import permuted_ols
Load Localizer contrast
n_samples = 94
localizer_dataset = datasets.fetch_localizer_contrasts(
["left button press (auditory cue)"],
n_subjects=n_samples,
)
# print basic information on the dataset
print(
"First contrast nifti image (3D) is located "
f"at: {localizer_dataset.cmaps[0]}"
)
tested_var = localizer_dataset.ext_vars["pseudo"]
# Quality check / Remove subjects with bad tested variate
mask_quality_check = np.where(np.logical_not(np.isnan(tested_var)))[0]
n_samples = mask_quality_check.size
contrast_map_filenames = [
localizer_dataset.cmaps[i] for i in mask_quality_check
]
tested_var = tested_var[mask_quality_check].to_numpy().reshape((-1, 1))
print(f"Actual number of subjects after quality check: {int(n_samples)}")
[fetch_localizer_contrasts] Dataset directory found:
/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer
First contrast nifti image (3D) is located at: /home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S01/cmaps_LeftAuditoryClick.nii.gz
Actual number of subjects after quality check: 89
Mask data
nifti_masker = NiftiMasker(
smoothing_fwhm=5, memory="nilearn_cache", memory_level=1, verbose=1
)
fmri_masked = nifti_masker.fit_transform(contrast_map_filenames)
\[NiftiMasker.wrapped] Loading data from ['/home/runner/work/nilearn/nilearn/nil
earn_data/brainomics_localizer/brainomics_data/S01/cmaps_LeftAuditoryClick.nii.g
z', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainom
ics_data/S02/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn
/nilearn_data/brainomics_localizer/brainomics_data/S03/cmaps_LeftAuditoryClick.n
ii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/bra
inomics_data/S04/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nil
earn/nilearn_data/brainomics_localizer/brainomics_data/S05/cmaps_LeftAuditoryCli
ck.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer
/brainomics_data/S06/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn
/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S07/cmaps_LeftAuditor
yClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_local
izer/brainomics_data/S08/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nil
earn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S09/cmaps_LeftAud
itoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_l
ocalizer/brainomics_data/S10/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work
/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S11/cmaps_Lef
tAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomi
cs_localizer/brainomics_data/S12/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/
work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S13/cmaps
_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brai
nomics_localizer/brainomics_data/S14/cmaps_LeftAuditoryClick.nii.gz', '/home/run
ner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S16/c
maps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/
brainomics_localizer/brainomics_data/S17/cmaps_LeftAuditoryClick.nii.gz', '/home
/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S
18/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_d
ata/brainomics_localizer/brainomics_data/S19/cmaps_LeftAuditoryClick.nii.gz', '/
home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_da
ta/S20/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilea
rn_data/brainomics_localizer/brainomics_data/S21/cmaps_LeftAuditoryClick.nii.gz'
, '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomic
s_data/S22/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/n
ilearn_data/brainomics_localizer/brainomics_data/S23/cmaps_LeftAuditoryClick.nii
.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brain
omics_data/S24/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilea
rn/nilearn_data/brainomics_localizer/brainomics_data/S25/cmaps_LeftAuditoryClick
.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/b
rainomics_data/S26/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/n
ilearn/nilearn_data/brainomics_localizer/brainomics_data/S27/cmaps_LeftAuditoryC
lick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localiz
er/brainomics_data/S28/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilea
rn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S29/cmaps_LeftAudit
oryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_loc
alizer/brainomics_data/S30/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/n
ilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S31/cmaps_LeftA
uditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics
_localizer/brainomics_data/S32/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/wo
rk/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S33/cmaps_L
eftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/braino
mics_localizer/brainomics_data/S34/cmaps_LeftAuditoryClick.nii.gz', '/home/runne
r/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S35/cma
ps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/br
ainomics_localizer/brainomics_data/S36/cmaps_LeftAuditoryClick.nii.gz', '/home/r
unner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S37
/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_dat
a/brainomics_localizer/brainomics_data/S39/cmaps_LeftAuditoryClick.nii.gz', '/ho
me/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data
/S40/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn
_data/brainomics_localizer/brainomics_data/S41/cmaps_LeftAuditoryClick.nii.gz',
'/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_
data/S42/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nil
earn_data/brainomics_localizer/brainomics_data/S43/cmaps_LeftAuditoryClick.nii.g
z', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainom
ics_data/S44/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn
/nilearn_data/brainomics_localizer/brainomics_data/S45/cmaps_LeftAuditoryClick.n
ii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/bra
inomics_data/S46/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nil
earn/nilearn_data/brainomics_localizer/brainomics_data/S47/cmaps_LeftAuditoryCli
ck.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer
/brainomics_data/S48/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn
/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S49/cmaps_LeftAuditor
yClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_local
izer/brainomics_data/S50/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nil
earn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S51/cmaps_LeftAud
itoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_l
ocalizer/brainomics_data/S52/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work
/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S53/cmaps_Lef
tAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomi
cs_localizer/brainomics_data/S54/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/
work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S55/cmaps
_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brai
nomics_localizer/brainomics_data/S56/cmaps_LeftAuditoryClick.nii.gz', '/home/run
ner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S57/c
maps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/
brainomics_localizer/brainomics_data/S58/cmaps_LeftAuditoryClick.nii.gz', '/home
/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S
59/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_d
ata/brainomics_localizer/brainomics_data/S60/cmaps_LeftAuditoryClick.nii.gz', '/
home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_da
ta/S61/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilea
rn_data/brainomics_localizer/brainomics_data/S63/cmaps_LeftAuditoryClick.nii.gz'
, '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomic
s_data/S64/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/n
ilearn_data/brainomics_localizer/brainomics_data/S65/cmaps_LeftAuditoryClick.nii
.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brain
omics_data/S66/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilea
rn/nilearn_data/brainomics_localizer/brainomics_data/S67/cmaps_LeftAuditoryClick
.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/b
rainomics_data/S68/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/n
ilearn/nilearn_data/brainomics_localizer/brainomics_data/S69/cmaps_LeftAuditoryC
lick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localiz
er/brainomics_data/S70/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilea
rn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S71/cmaps_LeftAudit
oryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_loc
alizer/brainomics_data/S72/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/n
ilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S73/cmaps_LeftA
uditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics
_localizer/brainomics_data/S74/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/wo
rk/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S75/cmaps_L
eftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/braino
mics_localizer/brainomics_data/S76/cmaps_LeftAuditoryClick.nii.gz', '/home/runne
r/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S77/cma
ps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/br
ainomics_localizer/brainomics_data/S78/cmaps_LeftAuditoryClick.nii.gz', '/home/r
unner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S79
/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_dat
a/brainomics_localizer/brainomics_data/S80/cmaps_LeftAuditoryClick.nii.gz', '/ho
me/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data
/S82/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn
_data/brainomics_localizer/brainomics_data/S83/cmaps_LeftAuditoryClick.nii.gz',
'/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_
data/S84/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn/nil
earn_data/brainomics_localizer/brainomics_data/S85/cmaps_LeftAuditoryClick.nii.g
z', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainom
ics_data/S86/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nilearn
/nilearn_data/brainomics_localizer/brainomics_data/S88/cmaps_LeftAuditoryClick.n
ii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/bra
inomics_data/S89/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn/nil
earn/nilearn_data/brainomics_localizer/brainomics_data/S90/cmaps_LeftAuditoryCli
ck.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer
/brainomics_data/S91/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nilearn
/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S92/cmaps_LeftAuditor
yClick.nii.gz', '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_local
izer/brainomics_data/S93/cmaps_LeftAuditoryClick.nii.gz', '/home/runner/work/nil
earn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S94/cmaps_LeftAud
itoryClick.nii.gz']
\[NiftiMasker.wrapped] Computing mask
________________________________________________________________________________
[Memory] Calling nilearn.masking.compute_background_mask...
compute_background_mask([ '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S01/cmaps_LeftAuditoryClick.nii.gz',
'/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S02/cmaps_LeftAuditoryClick.nii.gz',
'/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S03/cmaps_LeftAuditoryClick.nii.gz',
'/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S04/cmaps_LeftAuditoryClick.nii.gz',
'/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S05/cmaps_LeftAuditoryClick.nii.gz',
'/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomic..., verbose=0)
__________________________________________compute_background_mask - 0.4s, 0.0min
\[NiftiMasker.wrapped] Resampling mask
________________________________________________________________________________
[Memory] Calling nilearn.image.resampling.resample_img...
resample_img(<nibabel.nifti1.Nifti1Image object at 0x7f2b026a8be0>, target_affine=None, target_shape=None, copy=False, interpolation='nearest')
_____________________________________________________resample_img - 0.0s, 0.0min
\[NiftiMasker.wrapped] Finished fit
/home/runner/work/nilearn/nilearn/examples/07_advanced/plot_localizer_mass_univariate_methods.py:60: FutureWarning:
boolean values for 'standardize' will be deprecated in nilearn 0.15.0.
Use 'zscore_sample' instead of 'True' or use 'None' instead of 'False'.
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask([ '/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S01/cmaps_LeftAuditoryClick.nii.gz',
'/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S02/cmaps_LeftAuditoryClick.nii.gz',
'/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S03/cmaps_LeftAuditoryClick.nii.gz',
'/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S04/cmaps_LeftAuditoryClick.nii.gz',
'/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S05/cmaps_LeftAuditoryClick.nii.gz',
'/home/runner/work/nilearn/nilearn/nilearn_data/brainomics_localizer/brainomic...,
<nibabel.nifti1.Nifti1Image object at 0x7f2b026a8be0>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': 5,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, sklearn_output_config=None)
\[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f2b026a9660>
\[NiftiMasker.wrapped] Smoothing images
\[NiftiMasker.wrapped] Extracting region signals
\[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 1.0s, 0.0min
Anova (parametric F-scores)
from sklearn.feature_selection import f_regression
_, pvals_anova = f_regression(fmri_masked, tested_var.ravel(), center=True)
pvals_anova *= fmri_masked.shape[1]
pvals_anova[np.isnan(pvals_anova)] = 1
pvals_anova[pvals_anova > 1] = 1
neg_log_pvals_anova = -np.log10(pvals_anova)
neg_log_pvals_anova_unmasked = nifti_masker.inverse_transform(
neg_log_pvals_anova
)
\[NiftiMasker.inverse_transform] Computing image from signals
________________________________________________________________________________
[Memory] Calling nilearn.masking.unmask...
unmask(array([-0., ..., -0.]), <nibabel.nifti1.Nifti1Image object at 0x7f2b026a8be0>)
___________________________________________________________unmask - 0.0s, 0.0min
Perform massively univariate analysis with permuted OLS
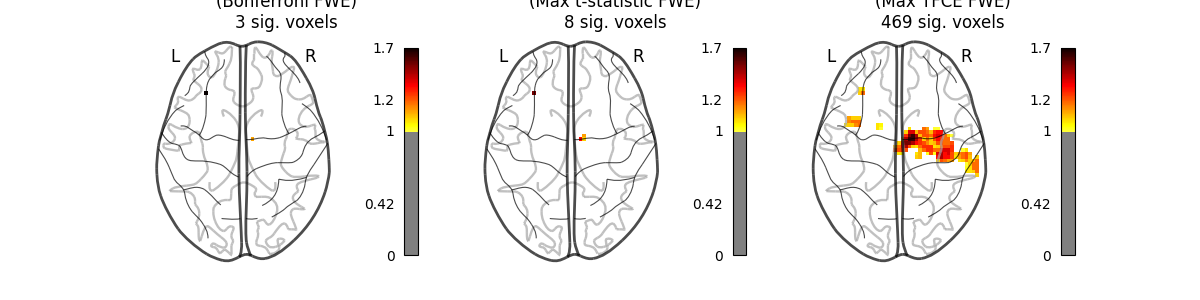
This method will produce both voxel-level FWE-corrected -log10 p-values and TFCE-based FWE-corrected -log10 p-values.
Note
permuted_ols can support a wide range
of analysis designs, depending on the tested_var.
For example, if you wished to perform a one-sample test, you could
simply provide an array of ones (e.g., np.ones(n_samples)).
ols_outputs = permuted_ols(
tested_var, # this is equivalent to the design matrix, in array form
fmri_masked,
model_intercept=True,
masker=nifti_masker,
tfce=True,
n_perm=100, # 100 for the sake of time. Ideally, this should be 10000.
verbose=1, # display progress bar
n_jobs=2, # can be changed to use more CPUs
)
neg_log_pvals_permuted_ols_unmasked = nifti_masker.inverse_transform(
ols_outputs["logp_max_t"][0, :] # select first regressor
)
neg_log_pvals_tfce_unmasked = nifti_masker.inverse_transform(
ols_outputs["logp_max_tfce"][0, :] # select first regressor
)
\[NiftiMasker.inverse_transform] Computing image from signals
________________________________________________________________________________
[Memory] Calling nilearn.masking.unmask...
unmask(array([[ 1.604273, ..., -0.864518]]), <nibabel.nifti1.Nifti1Image object at 0x7f2b026a8be0>)
___________________________________________________________unmask - 0.0s, 0.0min
[Parallel(n_jobs=2)]: Using backend LokyBackend with 2 concurrent workers.
[Parallel(n_jobs=2)]: Done 2 out of 2 | elapsed: 26.7s remaining: 0.0s
[Parallel(n_jobs=2)]: Done 2 out of 2 | elapsed: 26.7s finished
\[NiftiMasker.inverse_transform] Computing image from signals
________________________________________________________________________________
[Memory] Calling nilearn.masking.unmask...
unmask(array([-0., ..., -0.]), <nibabel.nifti1.Nifti1Image object at 0x7f2b026a8be0>)
___________________________________________________________unmask - 0.0s, 0.0min
\[NiftiMasker.inverse_transform] Computing image from signals
________________________________________________________________________________
[Memory] Calling nilearn.masking.unmask...
unmask(array([ 0.013095, ..., -0. ]), <nibabel.nifti1.Nifti1Image object at 0x7f2b026a8be0>)
___________________________________________________________unmask - 0.0s, 0.0min
Visualization
import matplotlib.pyplot as plt
from nilearn import plotting
from nilearn.image import get_data
threshold = -np.log10(0.1) # 10% corrected
vmax = max(
np.amax(ols_outputs["logp_max_t"]),
np.amax(neg_log_pvals_anova),
np.amax(ols_outputs["logp_max_tfce"]),
)
images_to_plot = {
"Parametric Test\n(Bonferroni FWE)": neg_log_pvals_anova_unmasked,
"Permutation Test\n(Max t-statistic FWE)": (
neg_log_pvals_permuted_ols_unmasked
),
"Permutation Test\n(Max TFCE FWE)": neg_log_pvals_tfce_unmasked,
}
fig, axes = plt.subplots(figsize=(10, 4), ncols=3)
for i_col, (title, img) in enumerate(images_to_plot.items()):
ax = axes[i_col]
n_detections = (get_data(img) > threshold).sum()
new_title = f"{title}\n{n_detections} sig. voxels"
plotting.plot_glass_brain(
img,
vmax=vmax,
display_mode="z",
threshold=threshold,
vmin=threshold,
cmap="inferno",
figure=fig,
axes=ax,
)
ax.set_title(new_title)
fig.suptitle(
"Group left button press ($-\\log_{10}$ p-values)",
y=1,
fontsize=16,
)
fig.subplots_adjust(top=0.75, wspace=0.5)
plotting.show()
Total running time of the script: (0 minutes 34.869 seconds)
Estimated memory usage: 397 MB