5.4. SpaceNet: decoding with spatial structure for better maps¶
5.4.1. The SpaceNet decoder¶
nilearn.decoding.SpaceNetRegressor and nilearn.decoding.SpaceNetClassifier
implements spatial penalties which improve brain decoding power as well as decoder maps:
penalty=”tvl1”: priors inspired from TV (Total Variation, see Michel et al.[1]), TV-L1 (see Baldassarre et al.[2] and Gramfort et al.[3]).
penalty=”graph-net”: GraphNet prior (see Grosenick et al.[4]).
These regularize classification and regression problems in brain imaging. The results are brain maps which are both sparse (i.e regression coefficients are zero everywhere, except at predictive voxels) and structured (blobby). The superiority of TV-L1 over methods without structured priors like the Lasso, SVM, ANOVA, Ridge, etc. for yielding more interpretable maps and improved prediction scores is now well established (see Baldassarre et al.[2], Gramfort et al.[3] Grosenick et al.[4]).
Note that TV-L1 prior leads to a difficult optimization problem, and so can be slow to run. Under the hood, a few heuristics are used to make things a bit faster. These include:
Feature preprocessing, where an F-test is used to eliminate non-predictive voxels, thus reducing the size of the brain mask in a principled way.
Continuation is used along the regularization path, where the solution of the optimization problem for a given value of the regularization parameter
alphais used as initialization for the next regularization (smaller) value on the regularization grid.
Implementation: See Dohmatob et al.[5] and Dohmatob et al.[6] for technical details regarding the implementation of SpaceNet.
5.4.2. Related example¶
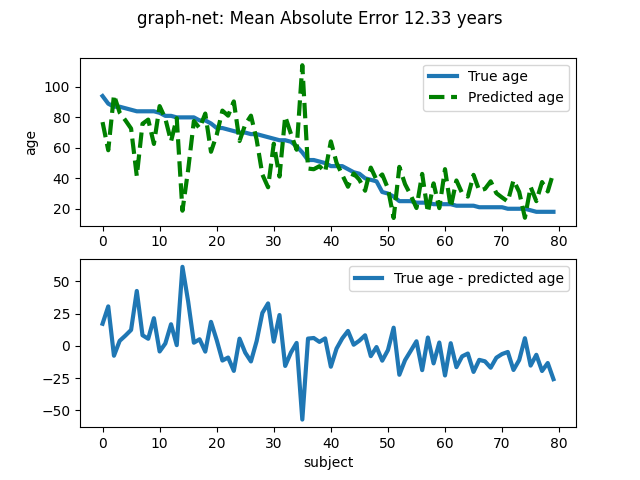
Age prediction on OASIS dataset with SpaceNet.
Note
Empirical comparisons using this method have been removed from documentation in version 0.7 to keep its computational cost low. You can easily try SpaceNet instead of FREM in mixed gambles study or Haxby study.
See also
FREM, a pipeline ensembling many models that yields very good decoding performance at a lower computational cost.