Note
This page is a reference documentation. It only explains the class signature, and not how to use it. Please refer to the user guide for the big picture.
nilearn.decoding.SpaceNetRegressor¶
- class nilearn.decoding.SpaceNetRegressor(penalty='graph-net', l1_ratios=0.5, alphas=None, n_alphas=10, mask=None, target_affine=None, target_shape=None, low_pass=None, high_pass=None, t_r=None, max_iter=200, tol=0.0001, memory=None, memory_level=1, standardize=True, verbose=0, n_jobs=1, eps=0.001, cv=8, fit_intercept=True, screening_percentile=20, debias=False, positive=False)[source]¶
Regression learners with sparsity and spatial priors.
SpaceNetRegressor implements Graph-Net and TV-L1 priors / penalties for regression problems. Thus, the penalty is a sum an L1 term and a spatial term. The aim of such a hybrid prior is to obtain weights maps which are structured (due to the spatial prior) and sparse (enforced by L1 norm).
- Parameters:
- penalty
str, default=’graph-net’ Penalty to used in the model. Can be ‘graph-net’ or ‘tv-l1’.
- l1_ratios
floatorlistof floats in the interval [0, 1]; default=0.5 Constant that mixes L1 and spatial prior terms in penalization. l1_ratios == 1 corresponds to pure LASSO. The larger the value of this parameter, the sparser the estimated weights map. If list is provided, then the best value will be selected by cross-validation.
- alphas
floatorlistoffloator None, default=None Choices for the constant that scales the overall regularization term. This parameter is mutually exclusive with the n_alphas parameter. If None or list of floats is provided, then the best value will be selected by cross-validation.
- n_alphas
int, default=10 Generate this number of alphas per regularization path. This parameter is mutually exclusive with the alphas parameter.`
- maskfilename, niimg, NiftiMasker instance, default=None
Mask to be used on data. If an instance of masker is passed, then its mask will be used. If no mask is it will be computed automatically by a MultiNiftiMasker with default parameters.
- target_affine3x3 or a 4x4 array-like, or None, default=None
If specified, the image is resampled corresponding to this new affine.
- target_shape
tupleorlistor None, default=None If specified, the image will be resized to match this new shape. len(target_shape) must be equal to 3.
Note
If target_shape is specified, a target_affine of shape (4, 4) must also be given.
- low_pass
floatorintor None, default=None Low cutoff frequency in Hertz. If specified, signals above this frequency will be filtered out. If None, no low-pass filtering will be performed.
- high_pass
floatorintor None, default=None High cutoff frequency in Hertz. If specified, signals below this frequency will be filtered out.
- t_r
floatorintor None, default=None Repetition time, in seconds (sampling period). Set to None if not provided.
- max_iter
int, default=200 Maximum number of iterations for the solver.
- tol
float, default=1e-4 Defines the tolerance for convergence.
- memoryNone, instance of
joblib.Memory,str, orpathlib.Path, default=None Used to cache the masking process. By default, no caching is done. If a
stris given, it is the path to the caching directory.- memory_level
int, default=1 Rough estimator of the amount of memory used by caching. Higher value means more memory for caching. Zero means no caching.
- standardizeany of: ‘zscore_sample’, ‘zscore’, ‘psc’, True, False or None; default=True
Strategy to standardize the signal:
'zscore_sample': The signal is z-scored. Timeseries are shifted to zero mean and scaled to unit variance. Uses sample std.'psc': Timeseries are shifted to zero mean value and scaled to percent signal change (as compared to original mean signal).True: The signal is z-scored (same as option zscore). Timeseries are shifted to zero mean and scaled to unit variance.Deprecated since Nilearn 0.13.0: In nilearn version 0.15.0,
Truewill be replaced by'zscore_sample'.False: Do not standardize the data.Deprecated since Nilearn 0.13.0: In nilearn version 0.15.0,
Falsewill be replaced byNone.
Deprecated since Nilearn 0.13.0: The default will be changed to
'zscore_sample'in version 0.15.0.- verbose
boolorint, default=0 Verbosity level (
0orFalsemeans no message).- n_jobs
int, default=1 The number of CPUs to use to do the computation. -1 means ‘all CPUs’.
- eps
float, default=1e-3 Length of the path. For example,
eps=1e-3means thatalpha_min / alpha_max = 1e-3- cvcross-validation generator,
intor None, default=8 A cross-validation generator. See: https://scikit-learn.org/stable/modules/cross_validation.html. If None is passed, cv=5 will be used. It can be an integer, in which case it is the number of folds in a KFold using
StratifiedKFoldwhen groups is None in thefitmethod for this class. If groups is specified butcvis not set to custom CV splitter, default isLeaveOneGroupOut.- fit_intercept
bool, default=True Fit or not an intercept.
- screening_percentileint, float, in the closed interval [0, 100], or None, default=20
Percentile value for ANOVA univariate feature selection. If
Noneis passed, it will be set to100. A value of100means “keep all features”. This percentile is expressed with respect to the volume of either a standard (MNI152) brain (ifmask_img_is a 3D volume) or a the number of vertices in the mask mesh (ifmask_img_is a SurfaceImage). This means that thescreening_percentileis corrected at runtime by premultiplying it with the ratio of volume of the standard brain to the volume of the mask of the data.Note
If the mask used is too small compared to the total brain volume / surface, then all its elements (voxels / vertices) may be included even for very small
screening_percentile.- debias
bool, default=False If set, then the estimated weights maps will be debiased.
- positive
bool, default=False When set to
True, forces the coefficients to be positive. This option is only supported for dense arrays.Added in Nilearn 0.12.1.
- penalty
- Attributes:
- all_coef_ndarray, shape (n_l1_ratios, n_folds, n_features)
Coefficients for all folds and features.
- alpha_grids_ndarray, shape (n_folds, n_alphas)
Alpha values considered for selection of the best ones (saved in best_model_params_)
- best_model_params_ndarray, shape (n_folds, n_parameter)
Best model parameters (alpha, l1_ratio) saved for the different cross-validation folds.
- coef_ndarray, shape (1, n_features) for 2 class classification problems (i.e n_classes = 2) (n_classes, n_features) for n_classes > 2
Coefficient of the features in the decision function.
- coef_img_nifti image
Masked model coefficients
- cv_list of pairs of lists
Each pair is the list of indices for the train and test samples for the corresponding fold.
- cv_scores_ndarray, shape (n_folds, n_alphas) or (n_l1_ratios, n_folds, n_alphas)
Scores (misclassification) for each alpha, and on each fold
- intercept_narray, shape
(1,) for 2 class classification problems (i.e n_classes = 2) (n_classes,) for n_classes > 2 Intercept (a.k.a. bias) added to the decision function. It is available only when parameter intercept is set to True.
- mask_ndarray 3D
An array contains values of the mask image.
- masker_instance of NiftiMasker
The nifti masker used to mask the data.
- mask_img_Nifti like image
The mask of the data. If no mask was supplied by the user, this attribute is the mask image computed automatically from the data X.
- memory_joblib memory cache
- n_elements_
int The number of features in the mask.
Added in Nilearn 0.12.1.
- screening_percentile_float
Screening percentile corrected according to volume of mask, relative to the volume of standard brain.
- w_ndarray, shape
(1, n_features + 1) for 2 class classification problems (i.e n_classes = 2) (n_classes, n_features + 1) for n_classes > 2, and (n_features,) for regression Model weights
- Xmean_array, shape (n_features,)
Mean of X across samples
- Xstd_array, shape (n_features,)
Standard deviation of X across samples
- ymean_array, shape (n_samples,)
Mean of prediction targets
See also
nilearn.decoding.SpaceNetClassifierGraph-Net and TV-L1 priors/penalties
- SUPPORTED_PENALTIES = ('graph-net', 'tv-l1')¶
- __init__(penalty='graph-net', l1_ratios=0.5, alphas=None, n_alphas=10, mask=None, target_affine=None, target_shape=None, low_pass=None, high_pass=None, t_r=None, max_iter=200, tol=0.0001, memory=None, memory_level=1, standardize=True, verbose=0, n_jobs=1, eps=0.001, cv=8, fit_intercept=True, screening_percentile=20, debias=False, positive=False)[source]¶
- fit(X, y)[source]¶
Fit the learner.
- Parameters:
- X
listof Niimg-like objects See Input and output: neuroimaging data representation. Data on which model is to be fitted. If this is a list, the affine is considered the same for all. Must have exactly as many elements as the input images.
- yarray or
listof length n_samples The dependent variable (age, sex, QI, etc.).
- X
Notes
- selfSpaceNet object
Model selection is via cross-validation with bagging.
- get_metadata_routing()¶
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)¶
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- predict(X)[source]¶
Predict class labels for samples in X.
- Parameters:
- XNiimg-like,
listNiimg-like objects or {array-like, sparse matrix}, shape = (n_samples, n_features) See Input and output: neuroimaging data representation. Data on prediction is to be made. If this is a list, the affine is considered the same for all.
- XNiimg-like,
- Returns:
- y_predndarray, shape (n_samples,)
Predicted class label per sample.
- score(X, y, sample_weight=None)¶
Return the coefficient of determination of the prediction.
The coefficient of determination
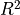 is defined as
is defined as
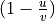 , where
, where 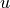 is the residual
sum of squares
is the residual
sum of squares ((y_true - y_pred)** 2).sum()and is the total sum of squares
is the total sum of squares ((y_true - y_true.mean()) ** 2).sum(). The best possible score is 1.0 and it can be negative (because the model can be arbitrarily worse). A constant model that always predicts the expected value of y, disregarding the input features, would get a score of 0.0.- Parameters:
- Xarray-like of shape (n_samples, n_features)
Test samples. For some estimators this may be a precomputed kernel matrix or a list of generic objects instead with shape
(n_samples, n_samples_fitted), wheren_samples_fittedis the number of samples used in the fitting for the estimator.- yarray-like of shape (n_samples,) or (n_samples, n_outputs)
True values for X.
- sample_weightarray-like of shape (n_samples,), default=None
Sample weights.
- Returns:
- scorefloat
- of
self.predict(X)w.r.t. y.
Notes
The
score used when calling scoreon a regressor usesmultioutput='uniform_average'from version 0.23 to keep consistent with default value ofr2_score. This influences thescoremethod of all the multioutput regressors (except forMultiOutputRegressor).
- set_fit_request(*, sample_weight='$UNCHANGED$')¶
Request metadata passed to the
fitmethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter infit.
- Returns:
- selfobject
The updated object.
- set_params(**params)¶
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.
- set_score_request(*, sample_weight='$UNCHANGED$')¶
Request metadata passed to the
scoremethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter inscore.
- Returns:
- selfobject
The updated object.
Examples using nilearn.decoding.SpaceNetRegressor¶
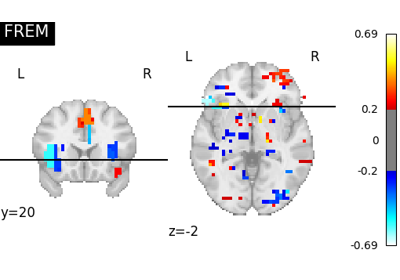
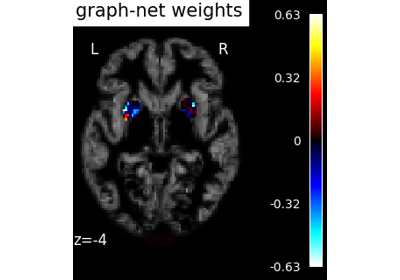
Voxel-Based Morphometry on Oasis dataset with Space-Net prior