Note
Go to the end to download the full example code or to run this example in your browser via Binder.
NeuroVault cross-study ICA maps¶
This example shows how to download statistical maps from NeuroVault, label them with NeuroSynth terms, and compute ICA components across all the maps.
See fetch_neurovault
documentation for more details.
Warning
If you are using Nilearn with a version older than 0.9.0,
then you should either upgrade your version or import maskers
from the input_data module instead of the maskers module.
That is, you should manually replace in the following example all occurrences of:
from nilearn.maskers import NiftiMasker
with:
from nilearn.input_data import NiftiMasker
import numpy as np
from scipy import stats
from sklearn.decomposition import FastICA
from nilearn.datasets import fetch_neurovault, load_mni152_brain_mask
from nilearn.image import smooth_img
from nilearn.maskers import NiftiMasker
from nilearn.plotting import plot_stat_map, show
Get image and term data¶
# Download images
# Here by default we only download 80 images to save time,
# but for better results I recommend using at least 200.
print(
"Fetching Neurovault images; "
"if you haven't downloaded any Neurovault data before "
"this will take several minutes."
)
nv_data = fetch_neurovault(
max_images=30, fetch_neurosynth_words=True, timeout=30.0
)
images = nv_data["images"]
term_weights = nv_data["word_frequencies"]
vocabulary = nv_data["vocabulary"]
if term_weights is None:
term_weights = np.ones((len(images), 2))
vocabulary = np.asarray(["Neurosynth is down", "Please try again later"])
# Clean and report term scores
term_weights[term_weights < 0] = 0
total_scores = np.mean(term_weights, axis=0)
print("\nTop 10 neurosynth terms from downloaded images:\n")
for term_idx in np.argsort(total_scores)[-10:][::-1]:
print(vocabulary[term_idx])
Fetching Neurovault images; if you haven't downloaded any Neurovault data before this will take several minutes.
[fetch_neurovault] Dataset found in /home/runner/nilearn_data/neurovault
[fetch_neurovault] Reading local neurovault data.
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=32980
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1952/neurosynth_words_for_image_
32980.json
[fetch_neurovault] Already fetched 1 image
[fetch_neurovault] 1 image found on local disk.
[fetch_neurovault] Reading server neurovault data.
[fetch_neurovault] Scroll collections: getting new batch:
https://neurovault.org/api/collections/?limit=100&offset=0
[fetch_neurovault] Scroll collections: batch size: 100
[fetch_neurovault] Scroll images from collection 921: getting new batch:
https://neurovault.org/api/collections/921/images/?limit=100&offset=0
[fetch_neurovault] Scroll images from collection 921: batch size: 1
[fetch_neurovault] On neurovault.org: no image matched query in collection 921
[fetch_neurovault] Scroll images from collection 440: getting new batch:
https://neurovault.org/api/collections/440/images/?limit=100&offset=0
[fetch_neurovault] Scroll images from collection 440: batch size: 2
[fetch_neurovault] On neurovault.org: no image matched query in collection 440
[fetch_neurovault] Scroll images from collection 496: getting new batch:
https://neurovault.org/api/collections/496/images/?limit=100&offset=0
[fetch_neurovault] Scroll images from collection 496: batch size: 1
[fetch_neurovault] On neurovault.org: no image matched query in collection 496
[fetch_neurovault] Scroll images from collection 4008: getting new batch:
https://neurovault.org/api/collections/4008/images/?limit=100&offset=0
[fetch_neurovault] Scroll images from collection 4008: batch size: 1
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/4008/spmT_0001.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_4008/image_65426.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=65426
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_4008/neurosynth_words_for_image_
65426.json
[fetch_neurovault] Already fetched 2 images
[fetch_neurovault] On neurovault.org: 1 image matched query in collection 4008
[fetch_neurovault] Scroll images from collection 4: getting new batch:
https://neurovault.org/api/collections/4/images/?limit=100&offset=0
[fetch_neurovault] Scroll images from collection 4: batch size: 1
[fetch_neurovault] On neurovault.org: no image matched query in collection 4
[fetch_neurovault] Scroll images from collection 79: getting new batch:
https://neurovault.org/api/collections/79/images/?limit=100&offset=0
[fetch_neurovault] Scroll images from collection 79: batch size: 5
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/79/neurosynth_spectral_01.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_79/image_11020.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=11020
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_79/neurosynth_words_for_image_11
020.json
[fetch_neurovault] Already fetched 3 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/79/neurosynth_spectral_01_1.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_79/image_11021.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=11021
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_79/neurosynth_words_for_image_11
021.json
[fetch_neurovault] Already fetched 4 images
[fetch_neurovault] On neurovault.org: 2 images matched query in collection 79
[fetch_neurovault] Scroll images from collection 1257: getting new batch:
https://neurovault.org/api/collections/1257/images/?limit=100&offset=0
[fetch_neurovault] Scroll images from collection 1257: batch size: 100
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/abstract_knowledge_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17327.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17327
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17327.json
[fetch_neurovault] Already fetched 5 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/acoustic_processing_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17328.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17328
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17328.json
[fetch_neurovault] Already fetched 6 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/action_perception_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17329.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17329
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17329.json
[fetch_neurovault] Already fetched 7 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/action_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17330.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17330
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17330.json
[fetch_neurovault] Already fetched 8 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/activation_level_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17331.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17331
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17331.json
[fetch_neurovault] Already fetched 9 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/activation_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17332.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17332
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17332.json
[fetch_neurovault] Already fetched 10 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/active_maintenance_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17333.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17333
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17333.json
[fetch_neurovault] Already fetched 11 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/active_retrieval_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17334.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17334
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17334.json
[fetch_neurovault] Already fetched 12 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/acuity_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17335.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17335
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17335.json
[fetch_neurovault] Already fetched 13 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/adaptation_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17336.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17336
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17336.json
[fetch_neurovault] Already fetched 14 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/adaptive_control_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17337.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17337
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17337.json
[fetch_neurovault] Already fetched 15 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/addiction_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17338.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17338
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17338.json
[fetch_neurovault] Already fetched 16 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/affect_perception_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17339.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17339
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17339.json
[fetch_neurovault] Already fetched 17 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/affect_recognition_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17340.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17340
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17340.json
[fetch_neurovault] Already fetched 18 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/agency_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17341.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17341
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17341.json
[fetch_neurovault] Already fetched 19 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/agreeableness_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17342.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17342
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17342.json
[fetch_neurovault] Already fetched 20 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/altruism_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17343.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17343
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17343.json
[fetch_neurovault] Already fetched 21 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/altruistic_motivation_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17344.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17344
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17344.json
[fetch_neurovault] Already fetched 22 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/alveolar_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17345.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17345
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17345.json
[fetch_neurovault] Already fetched 23 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/amodal_representation_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17346.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17346
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17346.json
[fetch_neurovault] Already fetched 24 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/analogical_reasoning_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17347.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17347
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17347.json
[fetch_neurovault] Already fetched 25 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/analogy_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17348.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17348
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17348.json
[fetch_neurovault] Already fetched 26 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/anchoring_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17349.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17349
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17349.json
[fetch_neurovault] Already fetched 27 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/anhedonia_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17350.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17350
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17350.json
[fetch_neurovault] Already fetched 28 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/animacy_decision_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17351.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17351
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17351.json
[fetch_neurovault] Already fetched 29 images
[fetch_neurovault] Downloading file:
http://neurovault.org/media/images/1257/animacy_perception_regparam.nii.gz
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/image_17352.nii.gz
[fetch_neurovault] Downloading file:
https://neurosynth.org/api/decode/?neurovault=17352
[fetch_neurovault] Download succeeded, downloaded to:
/home/runner/nilearn_data/neurovault/collection_1257/neurosynth_words_for_image_
17352.json
[fetch_neurovault] Already fetched 30 images
[fetch_neurovault] Computing word features.
[fetch_neurovault] Computing word features done; vocabulary size: 1298
Top 10 neurosynth terms from downloaded images:
parietal
motor
premotor
tasks
movements
intraparietal
task
intraparietal sulcus
premotor cortex
parietal cortex
Reshape and mask images¶
import warnings
print("\nReshaping and masking images.\n")
mask_img = load_mni152_brain_mask(resolution=2)
masker = NiftiMasker(
mask_img=mask_img, memory="nilearn_cache", memory_level=1, verbose=1
)
masker = masker.fit()
# Images may fail to be transformed, and are of different shapes,
# so we need to transform one-by-one and keep track of failures.
X = []
is_usable = np.ones((len(images),), dtype=bool)
for index, image_path in enumerate(images):
# load image and remove nan and inf values.
# applying smooth_img to an image with fwhm=None simply cleans up
# non-finite values but otherwise doesn't modify the image.
image = smooth_img(image_path, fwhm=None)
try:
with warnings.catch_warnings():
warnings.simplefilter("ignore")
X.append(masker.transform(image))
except Exception as e:
meta = nv_data["images_meta"][index]
print(
f"Failed to mask/reshape image: id: {meta.get('id')}; "
f"name: '{meta.get('name')}'; "
f"collection: {meta.get('collection_id')}; error: {e}"
)
is_usable[index] = False
# Now reshape list into 2D matrix, and remove failed images from terms
X = np.vstack(X)
term_weights = term_weights[is_usable, :]
Reshaping and masking images.
[NiftiMasker.fit] Loading mask from <nibabel.nifti1.Nifti1Image object at
0x7f1ef053a350>
[NiftiMasker.fit] Resampling mask
________________________________________________________________________________
[Memory] Calling nilearn.image.resampling.resample_img...
resample_img(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, target_affine=None, target_shape=None, copy=False, interpolation='nearest')
_____________________________________________________resample_img - 0.0s, 0.0min
[NiftiMasker.fit] Finished fit
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e920>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef053a830>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e830>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef053ba90>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e920>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef0538d60>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360f070>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef053bbb0>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e920>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef0538fd0>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360f070>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef0539240>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e920>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef0539e40>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360f070>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef0539c90>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e920>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef0539a20>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360f070>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef0538910>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e920>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef0538700>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360f070>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef0538a60>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e920>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef053a830>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360f070>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef053a530>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e920>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef053b1c0>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360f070>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef053abc0>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e920>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef053ace0>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360f070>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef053b040>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e920>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef053b3d0>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360f070>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef0538070>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e920>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef0538e80>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360f070>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef0539a20>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e920>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef0538c10>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360f070>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef053b190>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e920>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef0538280>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360f070>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef053bb80>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e920>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef053a530>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360f070>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef053b1c0>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
________________________________________________________________________________
[Memory] Calling nilearn.maskers.nifti_masker.filter_and_mask...
filter_and_mask(<nibabel.nifti1.Nifti1Image object at 0x7f1ee360e920>, <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>, { 'clean_args': None,
'clean_kwargs': {},
'cmap': 'gray',
'detrend': False,
'dtype': None,
'high_pass': None,
'high_variance_confounds': False,
'low_pass': None,
'reports': True,
'runs': None,
'smoothing_fwhm': None,
'standardize': False,
'standardize_confounds': True,
't_r': None,
'target_affine': None,
'target_shape': None}, memory_level=1, memory=Memory(location=nilearn_cache/joblib), verbose=1, confounds=None, sample_mask=None, copy=True, dtype=None, sklearn_output_config=None)
[NiftiMasker.wrapped] Loading data from <nibabel.nifti1.Nifti1Image object at
0x7f1ef053b580>
[NiftiMasker.wrapped] Resampling images
[NiftiMasker.wrapped] Extracting region signals
[NiftiMasker.wrapped] Cleaning extracted signals
__________________________________________________filter_and_mask - 0.5s, 0.0min
Run ICA and map components to terms¶
print("Running ICA; may take time...")
# We use a very small number of components as we have downloaded only 80
# images. For better results, increase the number of images downloaded
# and the number of components
n_components = 8
fast_ica = FastICA(n_components=n_components, random_state=0)
ica_maps = fast_ica.fit_transform(X.T).T
term_weights_for_components = np.dot(fast_ica.components_, term_weights)
print("Done, plotting results.")
Running ICA; may take time...
Done, plotting results.
Generate figures¶
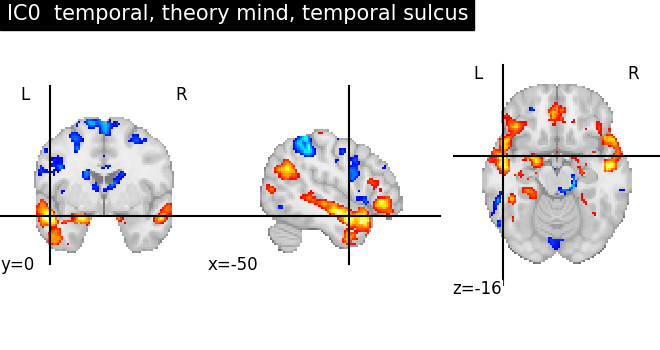
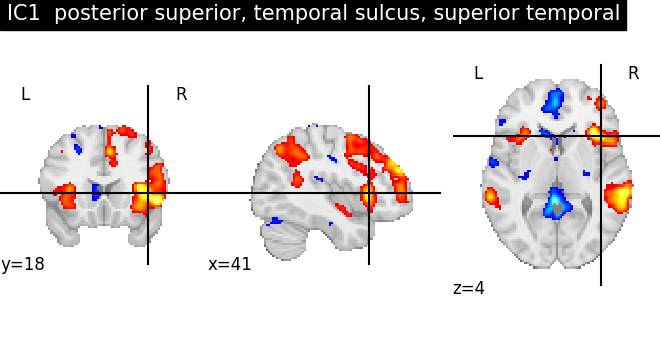
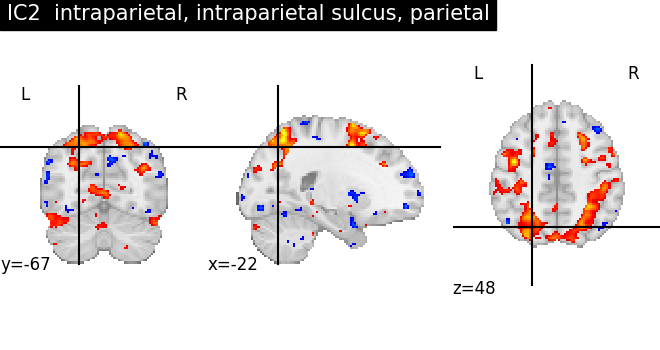
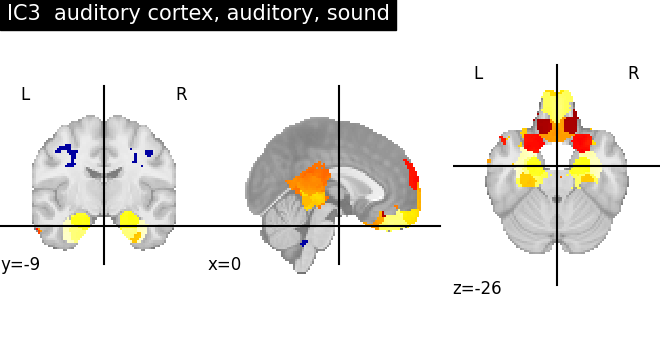
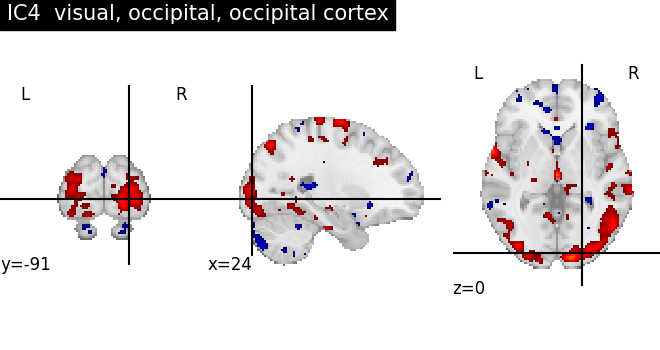
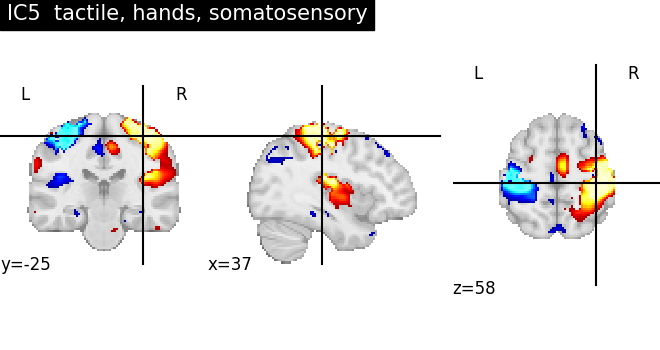
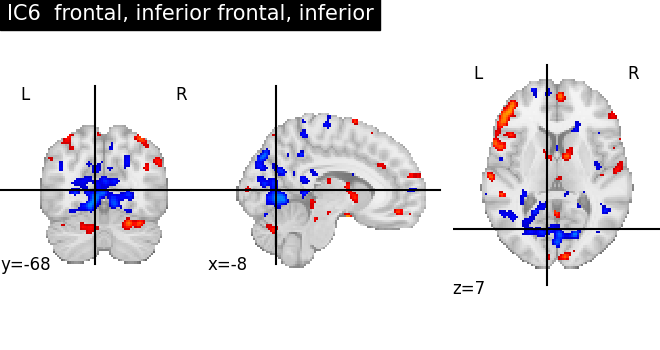
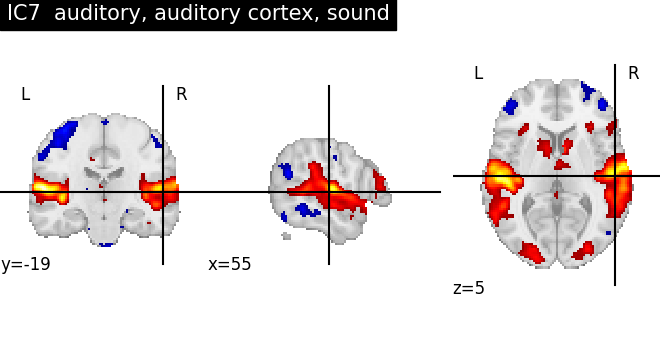
for index, (ic_map, ic_terms) in enumerate(
zip(ica_maps, term_weights_for_components, strict=False)
):
if -ic_map.min() > ic_map.max():
# Flip the map's sign for prettiness
ic_map = -ic_map
ic_terms = -ic_terms
ic_threshold = stats.scoreatpercentile(np.abs(ic_map), 90)
ic_img = masker.inverse_transform(ic_map)
important_terms = vocabulary[np.argsort(ic_terms)[-3:]]
title = f"IC{int(index)} {', '.join(important_terms[::-1])}"
plot_stat_map(ic_img, threshold=ic_threshold, colorbar=False, title=title)
[NiftiMasker.inverse_transform] Computing image from signals
________________________________________________________________________________
[Memory] Calling nilearn.masking.unmask...
unmask(array([ 0.446254, ..., -0.116826], shape=(235375,)), <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>)
___________________________________________________________unmask - 0.2s, 0.0min
[NiftiMasker.inverse_transform] Computing image from signals
________________________________________________________________________________
[Memory] Calling nilearn.masking.unmask...
unmask(array([0.003794, ..., 0.138935], shape=(235375,)), <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>)
___________________________________________________________unmask - 0.2s, 0.0min
[NiftiMasker.inverse_transform] Computing image from signals
________________________________________________________________________________
[Memory] Calling nilearn.masking.unmask...
unmask(array([-0.943755, ..., -1.277218], shape=(235375,)), <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>)
___________________________________________________________unmask - 0.2s, 0.0min
[NiftiMasker.inverse_transform] Computing image from signals
________________________________________________________________________________
[Memory] Calling nilearn.masking.unmask...
unmask(array([-0.013288, ..., -0.005942], shape=(235375,)), <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>)
___________________________________________________________unmask - 0.2s, 0.0min
[NiftiMasker.inverse_transform] Computing image from signals
________________________________________________________________________________
[Memory] Calling nilearn.masking.unmask...
unmask(array([-0.041787, ..., -0.324892], shape=(235375,)), <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>)
___________________________________________________________unmask - 0.2s, 0.0min
[NiftiMasker.inverse_transform] Computing image from signals
________________________________________________________________________________
[Memory] Calling nilearn.masking.unmask...
unmask(array([-0.18023 , ..., 0.289596], shape=(235375,)), <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>)
___________________________________________________________unmask - 0.2s, 0.0min
[NiftiMasker.inverse_transform] Computing image from signals
________________________________________________________________________________
[Memory] Calling nilearn.masking.unmask...
unmask(array([-0.265301, ..., -0.290405], shape=(235375,)), <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>)
___________________________________________________________unmask - 0.2s, 0.0min
[NiftiMasker.inverse_transform] Computing image from signals
________________________________________________________________________________
[Memory] Calling nilearn.masking.unmask...
unmask(array([0.024094, ..., 0.014214], shape=(235375,)), <nibabel.nifti1.Nifti1Image object at 0x7f1ee360e050>)
___________________________________________________________unmask - 0.2s, 0.0min
As we can see, some of the components capture cognitive or neurological maps, while other capture noise in the database. More data, better filtering, and better cognitive labels would give better maps
# Done.
show()
/home/runner/work/nilearn/nilearn/examples/07_advanced/plot_ica_neurovault.py:140: UserWarning:
You are using the 'agg' matplotlib backend that is non-interactive.
No figure will be plotted when calling matplotlib.pyplot.show() or nilearn.plotting.show().
You can fix this by installing a different backend: for example via
pip install PyQt6
Total running time of the script: (0 minutes 54.745 seconds)
Estimated memory usage: 269 MB