Note
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
Tuning a parameter with cross-validation¶
This example presents a nested cross-validation (CV) approach to perform
hyperparameter tuning and model performance evaluation with
Decoder objects.
The Decoder is a composite estimator that:
Applies a masker to the input images
Performs ANOVA univariate feature selection
Fits a classifier to the preprocessed data.
More information about the inner workings of the
Decoder class can be found at
this page.
The Decoder class implements a model selection
scheme that averages the best models within a cross-validation loop (a
technique sometimes known as CV bagging). However, there is no built-in way to
tune hyperparameters related to feature selection: this has to be done manually
using the nested cross-validation method, where the inner CV loop is used to
tune hyperparameters and the outer CV loop is used to evaluate model
performance. See https://scikit-learn.org/stable/modules/cross_validation.html
for an excellent explanation of how cross-validation works.
import warnings
warnings.filterwarnings(
"ignore", message="The provided image has no sform in its header."
)
# set overall verbosity for this example
verbose = 0
Load the Haxby dataset¶
We start by loading fMRI data and target labels from the Haxby dataset.
import pandas as pd
from nilearn import datasets
from nilearn.image import index_img
# load data from a single subject
haxby_dataset = datasets.fetch_haxby(verbose=verbose)
fmri_img = haxby_dataset.func[0]
mask_img = haxby_dataset.mask
print(f"Mask nifti image (3D) is located at: {haxby_dataset.mask}")
print(f"Functional nifti image (4D) are located at: {haxby_dataset.func[0]}")
# Load the behavioral data
labels = pd.read_csv(haxby_dataset.session_target[0], sep=" ")
y = labels["labels"]
# Keep only data corresponding to shoes or bottles
condition_mask = y.isin(["shoe", "bottle"])
fmri_niimgs = index_img(fmri_img, condition_mask)
y = y[condition_mask]
runs = labels["chunks"][condition_mask] # 12 runs total
Mask nifti image (3D) is located at: /home/runner/nilearn_data/haxby2001/mask.nii.gz
Functional nifti image (4D) are located at: /home/runner/nilearn_data/haxby2001/subj2/bold.nii.gz
Tuning the screening_percentile parameter¶
The rest of this example will consist of a step-by-step walkthrough of how to
tune a feature selection hyperparameter, screening_percentile. For the
full nested cross-validation (best practice) approach, see the end of this
page.
Helper function¶
Let’s define a helper function that creates and fits a single instance of a
Decoder with a given value of the screening_percentile parameter. This
function will allow us to avoid duplication of the code since we only want to
vary the screening_percentile hyperparameter.
import warnings
from nilearn.decoding import Decoder
def fit_decoder(X, y, screening_percentile, verbose=0):
decoder = Decoder(
estimator="svc",
cv=3,
mask=mask_img, # previously loaded, same for all decoders
smoothing_fwhm=4,
screening_percentile=screening_percentile,
verbose=verbose,
)
decoder.fit(X, y)
return decoder
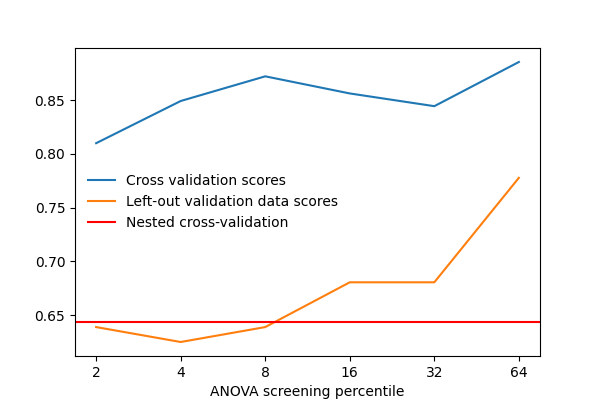
Trying different values of the screening_percentile hyperparameter¶
Here we fit the decoder on a subset of the data (the first 10 runs) using
different values for the screening_percentile parameter. We can see which
screening percentile gives the best validation score.
screening_percentiles = [2, 4, 8, 16, 32, 64]
idx_train = runs < 10 # first 10 runs
idx_val = ~idx_train # remaining 2 runs
X_train = index_img(fmri_niimgs, idx_train)
y_train = y[idx_train]
X_val = index_img(fmri_niimgs, idx_val)
y_val = y[idx_val]
validation_scores = {} # {screening_percentile: validation_score}
for screening_percentile in screening_percentiles:
decoder = fit_decoder(
X_train,
y_train,
screening_percentile=screening_percentile,
verbose=verbose,
)
validation_scores[screening_percentile] = decoder.score(X_val, y_val)
print("\nValidation scores:")
for screening_percentile, val_score in validation_scores.items():
print(f"- {screening_percentile=}: {val_score:.4f}")
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 52 71 127 152 3710 9201 9343 10661 13045 13993 14764 23573] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [660] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 52 71 127 152 3710 9201 9343 10661 13045 13993 14764 23573] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [660] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 52 71 127 152 3710 9201 9343 10661 13045 13993 14764 23573] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [660] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 52 71 127 152 3710 9201 9343 10661 13045 13993 14764 23573] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [660] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 52 71 127 152 3710 9201 9343 10661 13045 13993 14764 23573] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [660] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 52 71 127 152 3710 9201 9343 10661 13045 13993 14764 23573] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [660] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
Validation scores:
- screening_percentile=2: 0.4105
- screening_percentile=4: 0.4846
- screening_percentile=8: 0.4352
- screening_percentile=16: 0.5123
- screening_percentile=32: 0.5401
- screening_percentile=64: 0.4969
The above block of code can help determine which screening percentile is optimal when the decoder is fitted and validated on specific data. However, there are some important caveats to note:
The above code use a single train-test split. Different splits will give different validation scores, and it is possible that the best screening percentile is different for different splits.
The validation score should not be used as an estimate of the generalization performance of the model, since validation data was used to select the best screening percentile (in other words, it is not truly held-out data).
These points are addressed by using nested cross-validation.
Full nested cross-validation¶
Nested cross-validation works as follows:
The inner CV loop is used for hyperparameter tuning. Multiple validation scores are obtained for each value of the hyperparameter, and the best value is selected based on the average validation score across folds. Note: this is similar in concept to
sklearn’sGridSearchCV, which cannot be used here because of input data incompatibility between theDecoderclass and othersklearnestimators.The outer CV loop is used for model evaluation. For each fold, the model is refit using the best hyperparameter value from the inner CV loop, and a test score is obtained on the left-out test set. We then report the average test score across folds as an estimate of the generalization performance of the model.
In addition, we plot the average validation scores across inner CV folds for each value of the hyperparameter. This can help us visualize the hyperparameter tuning process and the stability of the best hyperparameter value across different outer CV folds.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import GroupKFold
plt.figure(figsize=(6, 4))
plt.xticks(np.arange(len(screening_percentiles)), screening_percentiles)
plt.xlabel("ANOVA screening percentile")
plt.ylabel("Average validation score across inner CV folds")
outer_cv = GroupKFold(n_splits=3)
test_scores = []
# outer CV loop for model evaluation
# the test set here are left out from the entire model fitting and
# selection process
for idx_train_val, idx_test in outer_cv.split(
np.arange(len(runs)), groups=runs
):
# inner CV loop for hyperparameter tuning
# the train set is used to fit the model and the validation set is used to
# select the best screening percentile for this CV split
mean_val_scores = {}
for screening_percentile in screening_percentiles:
inner_cv = GroupKFold(n_splits=3)
val_scores = []
for idx_train, idx_val in inner_cv.split(
idx_train_val, groups=runs.iloc[idx_train_val]
):
# inner_cv.split() returns indices relative to idx_train_val, so we
# need to index into idx_train_val to get the actual indices for
# the train and validation sets
idx_train = idx_train_val[idx_train]
idx_val = idx_train_val[idx_val]
X_train = index_img(fmri_niimgs, idx_train)
y_train = y.iloc[idx_train]
X_val = index_img(fmri_niimgs, idx_val)
y_val = y.iloc[idx_val]
decoder = fit_decoder(
X_train,
y_train,
screening_percentile=screening_percentile,
verbose=verbose,
)
val_scores.append(decoder.score(X_val, y_val))
mean_val_scores[screening_percentile] = np.mean(val_scores)
best_screening_percentile = max(mean_val_scores, key=mean_val_scores.get)
# plot average validation score for each screening percentile value
# use a different marker shape for the best screening percentile
i_fold = len(test_scores)
color = f"C{i_fold}"
plt.scatter(
np.arange(len(screening_percentiles)),
mean_val_scores.values(),
c=[
color
if screening_percentile != best_screening_percentile
else "white"
for screening_percentile in screening_percentiles
],
label=f"Outer CV fold {i_fold + 1}",
)
plt.scatter(
screening_percentiles.index(best_screening_percentile),
mean_val_scores[best_screening_percentile],
c=color,
s=100,
marker="*",
)
# pick the best screening percentile from the inner CV loop
print("Average validation scores by screening percentile:")
for screening_percentile, score in mean_val_scores.items():
str_best = ""
if screening_percentile == best_screening_percentile:
str_best = " (best)"
print(f"{screening_percentile=}:\t{score:.4f}{str_best}")
# refit the model and evaluate on the test set
X_train_val = index_img(fmri_niimgs, idx_train_val)
y_train_val = y.iloc[idx_train_val]
X_test = index_img(fmri_niimgs, idx_test)
y_test = y.iloc[idx_test]
decoder = fit_decoder(
X_train_val,
y_train_val,
screening_percentile=best_screening_percentile,
verbose=verbose,
)
test_scores.append(decoder.score(X_test, y_test))
plt.legend()
# final model performance estimation
print(
"Mean ± std test score:\t"
f"{np.mean(test_scores):.4f} ± {np.std(test_scores):.4f}"
)
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 152 724 969 1225 1494 1962 1990 2851 2866 3710 3711 3726
5696 5697 6066 9201 9208 9844 10191 10417 10485 11683 11793 11799
12310 12693 12710 13114 13993 14060 14151 14341 14362 15754 16521 16737
18328 18782 20619 20933 21261 21398 21433 21434 22501 22819 23573 24618
24660 24700 24701 25588 25770 26104 26105 26144 27184 27619 27626 27661
27932 28497 29472 29758 29829 29837 30276 33358 33392 33394 33745 34014
34497 34738 35771 36511 37315 37352 37986 37995 38006 38032 38117 38463
38981 38992 39047] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 52 67 152 163 169 344 969 1225 1456 1476 2983 4317
6352 9347 10661 12117 14662 23323 23843 32893 36774 38501 38867 39412
39444 39501 39584 39640] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [10920 12859 31755] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 1 4 5 6 22 33 48 52 71 77 86 127
152 161 162 163 168 173 174 518 538 539 580 685
948 1340 1494 2855 2864 3203 3491 3710 3711 5104 5697 5888
5922 5959 6606 6670 6672 7772 7790 7814 7815 7827 7877 8200
8203 8424 8468 8506 8805 8816 8842 9058 9139 9153 9195 9201
9243 9342 9343 9374 9377 9445 9447 10204 10251 10417 10424 10438
10447 10625 10626 10657 10661 10694 10733 10770 10809 10812 10844 11420
11428 11694 11710 11717 11730 11933 11968 12047 12541 12938 13004 13045
13058 13068 13114 13281 13942 13993 14016 14060 14106 14151 14308 14341
14430 14482 14489 15829 15835 16932 17236 17261 17283 17964 18610 18669
18691 19066 19593 19868 19891 19897 20045 20057 20808 21261 21377 21398
21403 21417 21424 21429 21449 21460 22154 22648 22723 22810 22815 22818
22846 22861 23322 23573 23775 24047 24059 24076 24191 24192 24193 24203
24221 24655 24697 24906 25145 25215 25488 25536 25551 25580 25586 25587
25593 25600 25798 26105 26287 26430 26914 26941 26947 27111 27144 27178
27290 27328 28214 28491 28528 28565 28959 29117 29154 29450 29725 30749
31312 31616 36927 38006 38032 39134] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 262 1925 21080 21081 29000] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 152 724 969 1225 1494 1962 1990 2851 2866 3710 3711 3726
5696 5697 6066 9201 9208 9844 10191 10417 10485 11683 11793 11799
12310 12693 12710 13114 13993 14060 14151 14341 14362 15754 16521 16737
18328 18782 20619 20933 21261 21398 21433 21434 22501 22819 23573 24618
24660 24700 24701 25588 25770 26104 26105 26144 27184 27619 27626 27661
27932 28497 29472 29758 29829 29837 30276 33358 33392 33394 33745 34014
34497 34738 35771 36511 37315 37352 37986 37995 38006 38032 38117 38463
38981 38992 39047] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 52 67 152 163 169 344 969 1225 1456 1476 2983 4317
6352 9347 10661 12117 14662 23323 23843 32893 36774 38501 38867 39412
39444 39501 39584 39640] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [10920 12859 31755] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 1 4 5 6 22 33 48 52 71 77 86 127
152 161 162 163 168 173 174 518 538 539 580 685
948 1340 1494 2855 2864 3203 3491 3710 3711 5104 5697 5888
5922 5959 6606 6670 6672 7772 7790 7814 7815 7827 7877 8200
8203 8424 8468 8506 8805 8816 8842 9058 9139 9153 9195 9201
9243 9342 9343 9374 9377 9445 9447 10204 10251 10417 10424 10438
10447 10625 10626 10657 10661 10694 10733 10770 10809 10812 10844 11420
11428 11694 11710 11717 11730 11933 11968 12047 12541 12938 13004 13045
13058 13068 13114 13281 13942 13993 14016 14060 14106 14151 14308 14341
14430 14482 14489 15829 15835 16932 17236 17261 17283 17964 18610 18669
18691 19066 19593 19868 19891 19897 20045 20057 20808 21261 21377 21398
21403 21417 21424 21429 21449 21460 22154 22648 22723 22810 22815 22818
22846 22861 23322 23573 23775 24047 24059 24076 24191 24192 24193 24203
24221 24655 24697 24906 25145 25215 25488 25536 25551 25580 25586 25587
25593 25600 25798 26105 26287 26430 26914 26941 26947 27111 27144 27178
27290 27328 28214 28491 28528 28565 28959 29117 29154 29450 29725 30749
31312 31616 36927 38006 38032 39134] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 262 1925 21080 21081 29000] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 152 724 969 1225 1494 1962 1990 2851 2866 3710 3711 3726
5696 5697 6066 9201 9208 9844 10191 10417 10485 11683 11793 11799
12310 12693 12710 13114 13993 14060 14151 14341 14362 15754 16521 16737
18328 18782 20619 20933 21261 21398 21433 21434 22501 22819 23573 24618
24660 24700 24701 25588 25770 26104 26105 26144 27184 27619 27626 27661
27932 28497 29472 29758 29829 29837 30276 33358 33392 33394 33745 34014
34497 34738 35771 36511 37315 37352 37986 37995 38006 38032 38117 38463
38981 38992 39047] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 52 67 152 163 169 344 969 1225 1456 1476 2983 4317
6352 9347 10661 12117 14662 23323 23843 32893 36774 38501 38867 39412
39444 39501 39584 39640] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [10920 12859 31755] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 1 4 5 6 22 33 48 52 71 77 86 127
152 161 162 163 168 173 174 518 538 539 580 685
948 1340 1494 2855 2864 3203 3491 3710 3711 5104 5697 5888
5922 5959 6606 6670 6672 7772 7790 7814 7815 7827 7877 8200
8203 8424 8468 8506 8805 8816 8842 9058 9139 9153 9195 9201
9243 9342 9343 9374 9377 9445 9447 10204 10251 10417 10424 10438
10447 10625 10626 10657 10661 10694 10733 10770 10809 10812 10844 11420
11428 11694 11710 11717 11730 11933 11968 12047 12541 12938 13004 13045
13058 13068 13114 13281 13942 13993 14016 14060 14106 14151 14308 14341
14430 14482 14489 15829 15835 16932 17236 17261 17283 17964 18610 18669
18691 19066 19593 19868 19891 19897 20045 20057 20808 21261 21377 21398
21403 21417 21424 21429 21449 21460 22154 22648 22723 22810 22815 22818
22846 22861 23322 23573 23775 24047 24059 24076 24191 24192 24193 24203
24221 24655 24697 24906 25145 25215 25488 25536 25551 25580 25586 25587
25593 25600 25798 26105 26287 26430 26914 26941 26947 27111 27144 27178
27290 27328 28214 28491 28528 28565 28959 29117 29154 29450 29725 30749
31312 31616 36927 38006 38032 39134] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 262 1925 21080 21081 29000] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 152 724 969 1225 1494 1962 1990 2851 2866 3710 3711 3726
5696 5697 6066 9201 9208 9844 10191 10417 10485 11683 11793 11799
12310 12693 12710 13114 13993 14060 14151 14341 14362 15754 16521 16737
18328 18782 20619 20933 21261 21398 21433 21434 22501 22819 23573 24618
24660 24700 24701 25588 25770 26104 26105 26144 27184 27619 27626 27661
27932 28497 29472 29758 29829 29837 30276 33358 33392 33394 33745 34014
34497 34738 35771 36511 37315 37352 37986 37995 38006 38032 38117 38463
38981 38992 39047] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 52 67 152 163 169 344 969 1225 1456 1476 2983 4317
6352 9347 10661 12117 14662 23323 23843 32893 36774 38501 38867 39412
39444 39501 39584 39640] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [10920 12859 31755] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 1 4 5 6 22 33 48 52 71 77 86 127
152 161 162 163 168 173 174 518 538 539 580 685
948 1340 1494 2855 2864 3203 3491 3710 3711 5104 5697 5888
5922 5959 6606 6670 6672 7772 7790 7814 7815 7827 7877 8200
8203 8424 8468 8506 8805 8816 8842 9058 9139 9153 9195 9201
9243 9342 9343 9374 9377 9445 9447 10204 10251 10417 10424 10438
10447 10625 10626 10657 10661 10694 10733 10770 10809 10812 10844 11420
11428 11694 11710 11717 11730 11933 11968 12047 12541 12938 13004 13045
13058 13068 13114 13281 13942 13993 14016 14060 14106 14151 14308 14341
14430 14482 14489 15829 15835 16932 17236 17261 17283 17964 18610 18669
18691 19066 19593 19868 19891 19897 20045 20057 20808 21261 21377 21398
21403 21417 21424 21429 21449 21460 22154 22648 22723 22810 22815 22818
22846 22861 23322 23573 23775 24047 24059 24076 24191 24192 24193 24203
24221 24655 24697 24906 25145 25215 25488 25536 25551 25580 25586 25587
25593 25600 25798 26105 26287 26430 26914 26941 26947 27111 27144 27178
27290 27328 28214 28491 28528 28565 28959 29117 29154 29450 29725 30749
31312 31616 36927 38006 38032 39134] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 262 1925 21080 21081 29000] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 152 724 969 1225 1494 1962 1990 2851 2866 3710 3711 3726
5696 5697 6066 9201 9208 9844 10191 10417 10485 11683 11793 11799
12310 12693 12710 13114 13993 14060 14151 14341 14362 15754 16521 16737
18328 18782 20619 20933 21261 21398 21433 21434 22501 22819 23573 24618
24660 24700 24701 25588 25770 26104 26105 26144 27184 27619 27626 27661
27932 28497 29472 29758 29829 29837 30276 33358 33392 33394 33745 34014
34497 34738 35771 36511 37315 37352 37986 37995 38006 38032 38117 38463
38981 38992 39047] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 52 67 152 163 169 344 969 1225 1456 1476 2983 4317
6352 9347 10661 12117 14662 23323 23843 32893 36774 38501 38867 39412
39444 39501 39584 39640] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [10920 12859 31755] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 1 4 5 6 22 33 48 52 71 77 86 127
152 161 162 163 168 173 174 518 538 539 580 685
948 1340 1494 2855 2864 3203 3491 3710 3711 5104 5697 5888
5922 5959 6606 6670 6672 7772 7790 7814 7815 7827 7877 8200
8203 8424 8468 8506 8805 8816 8842 9058 9139 9153 9195 9201
9243 9342 9343 9374 9377 9445 9447 10204 10251 10417 10424 10438
10447 10625 10626 10657 10661 10694 10733 10770 10809 10812 10844 11420
11428 11694 11710 11717 11730 11933 11968 12047 12541 12938 13004 13045
13058 13068 13114 13281 13942 13993 14016 14060 14106 14151 14308 14341
14430 14482 14489 15829 15835 16932 17236 17261 17283 17964 18610 18669
18691 19066 19593 19868 19891 19897 20045 20057 20808 21261 21377 21398
21403 21417 21424 21429 21449 21460 22154 22648 22723 22810 22815 22818
22846 22861 23322 23573 23775 24047 24059 24076 24191 24192 24193 24203
24221 24655 24697 24906 25145 25215 25488 25536 25551 25580 25586 25587
25593 25600 25798 26105 26287 26430 26914 26941 26947 27111 27144 27178
27290 27328 28214 28491 28528 28565 28959 29117 29154 29450 29725 30749
31312 31616 36927 38006 38032 39134] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 262 1925 21080 21081 29000] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 152 724 969 1225 1494 1962 1990 2851 2866 3710 3711 3726
5696 5697 6066 9201 9208 9844 10191 10417 10485 11683 11793 11799
12310 12693 12710 13114 13993 14060 14151 14341 14362 15754 16521 16737
18328 18782 20619 20933 21261 21398 21433 21434 22501 22819 23573 24618
24660 24700 24701 25588 25770 26104 26105 26144 27184 27619 27626 27661
27932 28497 29472 29758 29829 29837 30276 33358 33392 33394 33745 34014
34497 34738 35771 36511 37315 37352 37986 37995 38006 38032 38117 38463
38981 38992 39047] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 52 67 152 163 169 344 969 1225 1456 1476 2983 4317
6352 9347 10661 12117 14662 23323 23843 32893 36774 38501 38867 39412
39444 39501 39584 39640] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [10920 12859 31755] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 1 4 5 6 22 33 48 52 71 77 86 127
152 161 162 163 168 173 174 518 538 539 580 685
948 1340 1494 2855 2864 3203 3491 3710 3711 5104 5697 5888
5922 5959 6606 6670 6672 7772 7790 7814 7815 7827 7877 8200
8203 8424 8468 8506 8805 8816 8842 9058 9139 9153 9195 9201
9243 9342 9343 9374 9377 9445 9447 10204 10251 10417 10424 10438
10447 10625 10626 10657 10661 10694 10733 10770 10809 10812 10844 11420
11428 11694 11710 11717 11730 11933 11968 12047 12541 12938 13004 13045
13058 13068 13114 13281 13942 13993 14016 14060 14106 14151 14308 14341
14430 14482 14489 15829 15835 16932 17236 17261 17283 17964 18610 18669
18691 19066 19593 19868 19891 19897 20045 20057 20808 21261 21377 21398
21403 21417 21424 21429 21449 21460 22154 22648 22723 22810 22815 22818
22846 22861 23322 23573 23775 24047 24059 24076 24191 24192 24193 24203
24221 24655 24697 24906 25145 25215 25488 25536 25551 25580 25586 25587
25593 25600 25798 26105 26287 26430 26914 26941 26947 27111 27144 27178
27290 27328 28214 28491 28528 28565 28959 29117 29154 29450 29725 30749
31312 31616 36927 38006 38032 39134] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 262 1925 21080 21081 29000] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
Average validation scores by screening percentile:
screening_percentile=2: 0.5569
screening_percentile=4: 0.5690
screening_percentile=8: 0.5796
screening_percentile=16: 0.5830 (best)
screening_percentile=32: 0.5704
screening_percentile=64: 0.5737
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 52 71 127 152 580 969 1225 1494 3710 3711 7815 9201
10661 13045 13114 13993 14151 14341 17964 18782 21403 23573 26105 27111
27184 36927 37995 38006] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [12859] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 20 71 77 93 152 163 169 518 580 664 705
723 724 948 962 1113 1317 1493 1494 1510 1990 2864 3710
3711 3726 5424 5487 5560 5696 5697 6178 7401 7815 7920 9198
9800 10097 10191 11399 11799 12154 12678 12891 12938 13045 13902 13993
14025 14049 14918 15284 15327 15587 15739 16520 17290 18118 18157 18465
18578 18782 19447 19593 19628 19629 19891 20933 20952 21022 21261 21433
23573 23938 24618 24658 24697 24736 25182 25798 25992 26064 26145 27111
27619 27626 27661 27932 28238 28394 28959 29117 29765 29792 29829 30276
31021 31057 31195 31232 31499 32116 32117 32156 32158 32192 32227 32594
33254 33294 33324 33745 34738 36278 36932 37070 37226 37315 37385 37620
37995 38208 38520 38521 38690 38827 38867 39054 39168 39481] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [6140] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 13 152 163 169 1442 8131 8166 9343 9375 10661 39707] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 4 5 22 33 47 48 50 52 61 62 63
66 71 75 76 77 78 86 89 90 91 92 93
95 99 103 104 105 106 107 108 114 115 117 118
119 120 121 122 124 127 128 129 130 131 132 133
134 135 137 142 143 144 145 146 147 152 153 154
155 156 157 158 159 160 161 162 163 164 165 167
168 169 170 171 172 173 174 518 538 539 580 685
962 1315 1337 1340 1493 1494 2136 2863 3491 3710 3711 4496
5036 5562 5623 5696 5697 6625 7206 7827 7877 7965 7987 8131
8203 8424 8468 8506 8842 8875 8947 8986 8988 9201 9243 9342
9343 9374 9375 9377 9411 10040 10100 10204 10246 10384 10402 10417
10424 10447 10496 10625 10626 10657 10661 10694 10733 10770 10809 10811
11428 11521 11532 11604 11694 11710 11725 11792 11850 11935 12915 12938
12950 13045 13058 13114 13281 13427 13622 13791 13831 13942 13993 14012
14049 14151 14200 14284 14406 14524 14600 14764 14844 14929 14962 15722
15835 15943 16025 16087 16096 16713 16932 17080 17087 17103 17125 17127
17149 17206 17236 17261 17268 17290 17403 17405 17464 17638 17641 17676
18051 18157 18269 18465 18540 18559 18615 18630 18669 18677 18782 18846
19203 19593 19732 19868 19897 20364 20849 20933 20935 20952 20986 21022
21182 21207 21261 21290 21357 21358 21366 21379 21398 21417 21432 21460
21864 22066 22236 22648 22699 22700 22723 22744 22810 22815 22818 22846
22861 23243 23246 23322 23573 23848 24000 24076 24191 24192 24221 24655
24658 24697 25145 25215 25305 25488 25528 25558 25574 25578 25580 25586
25631 25766 25798 26064 26065 26105 26145 26314 26773 26914 26941 26947
26964 27111 27290 27292 27293 27586 27622 27661 27841 28118 28214 28345
28395 28490 28491 28526 28527 28528 28565 28959 29117 29450 29723 29725
29758 29793 29829 30276 30525 30830 30837 30886 30944 30979 31019 31312
31320 31585 31616 32006 32116 32127 32183 32218 32439 32525 32804 33349
33745 33864 34024 34084 34738 35135 35912 35999 36511 36666 36799 36854
37041 37198 37261 37315 37782 37995 38055 38169 38314 38338 38563 38603
38637 38641 38690 38754 38867 38883 39008 39134 39156 39168 39214 39303
39339 39405 39490 39491 39517 39534 39704 39723 39832 39833 39845 39846
39858 39859 39860 39887] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [32088] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 20 71 77 93 152 163 169 518 580 664 705
723 724 948 962 1113 1317 1493 1494 1510 1990 2864 3710
3711 3726 5424 5487 5560 5696 5697 6178 7401 7815 7920 9198
9800 10097 10191 11399 11799 12154 12678 12891 12938 13045 13902 13993
14025 14049 14918 15284 15327 15587 15739 16520 17290 18118 18157 18465
18578 18782 19447 19593 19628 19629 19891 20933 20952 21022 21261 21433
23573 23938 24618 24658 24697 24736 25182 25798 25992 26064 26145 27111
27619 27626 27661 27932 28238 28394 28959 29117 29765 29792 29829 30276
31021 31057 31195 31232 31499 32116 32117 32156 32158 32192 32227 32594
33254 33294 33324 33745 34738 36278 36932 37070 37226 37315 37385 37620
37995 38208 38520 38521 38690 38827 38867 39054 39168 39481] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [6140] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 13 152 163 169 1442 8131 8166 9343 9375 10661 39707] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 4 5 22 33 47 48 50 52 61 62 63
66 71 75 76 77 78 86 89 90 91 92 93
95 99 103 104 105 106 107 108 114 115 117 118
119 120 121 122 124 127 128 129 130 131 132 133
134 135 137 142 143 144 145 146 147 152 153 154
155 156 157 158 159 160 161 162 163 164 165 167
168 169 170 171 172 173 174 518 538 539 580 685
962 1315 1337 1340 1493 1494 2136 2863 3491 3710 3711 4496
5036 5562 5623 5696 5697 6625 7206 7827 7877 7965 7987 8131
8203 8424 8468 8506 8842 8875 8947 8986 8988 9201 9243 9342
9343 9374 9375 9377 9411 10040 10100 10204 10246 10384 10402 10417
10424 10447 10496 10625 10626 10657 10661 10694 10733 10770 10809 10811
11428 11521 11532 11604 11694 11710 11725 11792 11850 11935 12915 12938
12950 13045 13058 13114 13281 13427 13622 13791 13831 13942 13993 14012
14049 14151 14200 14284 14406 14524 14600 14764 14844 14929 14962 15722
15835 15943 16025 16087 16096 16713 16932 17080 17087 17103 17125 17127
17149 17206 17236 17261 17268 17290 17403 17405 17464 17638 17641 17676
18051 18157 18269 18465 18540 18559 18615 18630 18669 18677 18782 18846
19203 19593 19732 19868 19897 20364 20849 20933 20935 20952 20986 21022
21182 21207 21261 21290 21357 21358 21366 21379 21398 21417 21432 21460
21864 22066 22236 22648 22699 22700 22723 22744 22810 22815 22818 22846
22861 23243 23246 23322 23573 23848 24000 24076 24191 24192 24221 24655
24658 24697 25145 25215 25305 25488 25528 25558 25574 25578 25580 25586
25631 25766 25798 26064 26065 26105 26145 26314 26773 26914 26941 26947
26964 27111 27290 27292 27293 27586 27622 27661 27841 28118 28214 28345
28395 28490 28491 28526 28527 28528 28565 28959 29117 29450 29723 29725
29758 29793 29829 30276 30525 30830 30837 30886 30944 30979 31019 31312
31320 31585 31616 32006 32116 32127 32183 32218 32439 32525 32804 33349
33745 33864 34024 34084 34738 35135 35912 35999 36511 36666 36799 36854
37041 37198 37261 37315 37782 37995 38055 38169 38314 38338 38563 38603
38637 38641 38690 38754 38867 38883 39008 39134 39156 39168 39214 39303
39339 39405 39490 39491 39517 39534 39704 39723 39832 39833 39845 39846
39858 39859 39860 39887] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [32088] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 20 71 77 93 152 163 169 518 580 664 705
723 724 948 962 1113 1317 1493 1494 1510 1990 2864 3710
3711 3726 5424 5487 5560 5696 5697 6178 7401 7815 7920 9198
9800 10097 10191 11399 11799 12154 12678 12891 12938 13045 13902 13993
14025 14049 14918 15284 15327 15587 15739 16520 17290 18118 18157 18465
18578 18782 19447 19593 19628 19629 19891 20933 20952 21022 21261 21433
23573 23938 24618 24658 24697 24736 25182 25798 25992 26064 26145 27111
27619 27626 27661 27932 28238 28394 28959 29117 29765 29792 29829 30276
31021 31057 31195 31232 31499 32116 32117 32156 32158 32192 32227 32594
33254 33294 33324 33745 34738 36278 36932 37070 37226 37315 37385 37620
37995 38208 38520 38521 38690 38827 38867 39054 39168 39481] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [6140] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 13 152 163 169 1442 8131 8166 9343 9375 10661 39707] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 4 5 22 33 47 48 50 52 61 62 63
66 71 75 76 77 78 86 89 90 91 92 93
95 99 103 104 105 106 107 108 114 115 117 118
119 120 121 122 124 127 128 129 130 131 132 133
134 135 137 142 143 144 145 146 147 152 153 154
155 156 157 158 159 160 161 162 163 164 165 167
168 169 170 171 172 173 174 518 538 539 580 685
962 1315 1337 1340 1493 1494 2136 2863 3491 3710 3711 4496
5036 5562 5623 5696 5697 6625 7206 7827 7877 7965 7987 8131
8203 8424 8468 8506 8842 8875 8947 8986 8988 9201 9243 9342
9343 9374 9375 9377 9411 10040 10100 10204 10246 10384 10402 10417
10424 10447 10496 10625 10626 10657 10661 10694 10733 10770 10809 10811
11428 11521 11532 11604 11694 11710 11725 11792 11850 11935 12915 12938
12950 13045 13058 13114 13281 13427 13622 13791 13831 13942 13993 14012
14049 14151 14200 14284 14406 14524 14600 14764 14844 14929 14962 15722
15835 15943 16025 16087 16096 16713 16932 17080 17087 17103 17125 17127
17149 17206 17236 17261 17268 17290 17403 17405 17464 17638 17641 17676
18051 18157 18269 18465 18540 18559 18615 18630 18669 18677 18782 18846
19203 19593 19732 19868 19897 20364 20849 20933 20935 20952 20986 21022
21182 21207 21261 21290 21357 21358 21366 21379 21398 21417 21432 21460
21864 22066 22236 22648 22699 22700 22723 22744 22810 22815 22818 22846
22861 23243 23246 23322 23573 23848 24000 24076 24191 24192 24221 24655
24658 24697 25145 25215 25305 25488 25528 25558 25574 25578 25580 25586
25631 25766 25798 26064 26065 26105 26145 26314 26773 26914 26941 26947
26964 27111 27290 27292 27293 27586 27622 27661 27841 28118 28214 28345
28395 28490 28491 28526 28527 28528 28565 28959 29117 29450 29723 29725
29758 29793 29829 30276 30525 30830 30837 30886 30944 30979 31019 31312
31320 31585 31616 32006 32116 32127 32183 32218 32439 32525 32804 33349
33745 33864 34024 34084 34738 35135 35912 35999 36511 36666 36799 36854
37041 37198 37261 37315 37782 37995 38055 38169 38314 38338 38563 38603
38637 38641 38690 38754 38867 38883 39008 39134 39156 39168 39214 39303
39339 39405 39490 39491 39517 39534 39704 39723 39832 39833 39845 39846
39858 39859 39860 39887] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [32088] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 20 71 77 93 152 163 169 518 580 664 705
723 724 948 962 1113 1317 1493 1494 1510 1990 2864 3710
3711 3726 5424 5487 5560 5696 5697 6178 7401 7815 7920 9198
9800 10097 10191 11399 11799 12154 12678 12891 12938 13045 13902 13993
14025 14049 14918 15284 15327 15587 15739 16520 17290 18118 18157 18465
18578 18782 19447 19593 19628 19629 19891 20933 20952 21022 21261 21433
23573 23938 24618 24658 24697 24736 25182 25798 25992 26064 26145 27111
27619 27626 27661 27932 28238 28394 28959 29117 29765 29792 29829 30276
31021 31057 31195 31232 31499 32116 32117 32156 32158 32192 32227 32594
33254 33294 33324 33745 34738 36278 36932 37070 37226 37315 37385 37620
37995 38208 38520 38521 38690 38827 38867 39054 39168 39481] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [6140] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 13 152 163 169 1442 8131 8166 9343 9375 10661 39707] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 4 5 22 33 47 48 50 52 61 62 63
66 71 75 76 77 78 86 89 90 91 92 93
95 99 103 104 105 106 107 108 114 115 117 118
119 120 121 122 124 127 128 129 130 131 132 133
134 135 137 142 143 144 145 146 147 152 153 154
155 156 157 158 159 160 161 162 163 164 165 167
168 169 170 171 172 173 174 518 538 539 580 685
962 1315 1337 1340 1493 1494 2136 2863 3491 3710 3711 4496
5036 5562 5623 5696 5697 6625 7206 7827 7877 7965 7987 8131
8203 8424 8468 8506 8842 8875 8947 8986 8988 9201 9243 9342
9343 9374 9375 9377 9411 10040 10100 10204 10246 10384 10402 10417
10424 10447 10496 10625 10626 10657 10661 10694 10733 10770 10809 10811
11428 11521 11532 11604 11694 11710 11725 11792 11850 11935 12915 12938
12950 13045 13058 13114 13281 13427 13622 13791 13831 13942 13993 14012
14049 14151 14200 14284 14406 14524 14600 14764 14844 14929 14962 15722
15835 15943 16025 16087 16096 16713 16932 17080 17087 17103 17125 17127
17149 17206 17236 17261 17268 17290 17403 17405 17464 17638 17641 17676
18051 18157 18269 18465 18540 18559 18615 18630 18669 18677 18782 18846
19203 19593 19732 19868 19897 20364 20849 20933 20935 20952 20986 21022
21182 21207 21261 21290 21357 21358 21366 21379 21398 21417 21432 21460
21864 22066 22236 22648 22699 22700 22723 22744 22810 22815 22818 22846
22861 23243 23246 23322 23573 23848 24000 24076 24191 24192 24221 24655
24658 24697 25145 25215 25305 25488 25528 25558 25574 25578 25580 25586
25631 25766 25798 26064 26065 26105 26145 26314 26773 26914 26941 26947
26964 27111 27290 27292 27293 27586 27622 27661 27841 28118 28214 28345
28395 28490 28491 28526 28527 28528 28565 28959 29117 29450 29723 29725
29758 29793 29829 30276 30525 30830 30837 30886 30944 30979 31019 31312
31320 31585 31616 32006 32116 32127 32183 32218 32439 32525 32804 33349
33745 33864 34024 34084 34738 35135 35912 35999 36511 36666 36799 36854
37041 37198 37261 37315 37782 37995 38055 38169 38314 38338 38563 38603
38637 38641 38690 38754 38867 38883 39008 39134 39156 39168 39214 39303
39339 39405 39490 39491 39517 39534 39704 39723 39832 39833 39845 39846
39858 39859 39860 39887] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [32088] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 20 71 77 93 152 163 169 518 580 664 705
723 724 948 962 1113 1317 1493 1494 1510 1990 2864 3710
3711 3726 5424 5487 5560 5696 5697 6178 7401 7815 7920 9198
9800 10097 10191 11399 11799 12154 12678 12891 12938 13045 13902 13993
14025 14049 14918 15284 15327 15587 15739 16520 17290 18118 18157 18465
18578 18782 19447 19593 19628 19629 19891 20933 20952 21022 21261 21433
23573 23938 24618 24658 24697 24736 25182 25798 25992 26064 26145 27111
27619 27626 27661 27932 28238 28394 28959 29117 29765 29792 29829 30276
31021 31057 31195 31232 31499 32116 32117 32156 32158 32192 32227 32594
33254 33294 33324 33745 34738 36278 36932 37070 37226 37315 37385 37620
37995 38208 38520 38521 38690 38827 38867 39054 39168 39481] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [6140] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 13 152 163 169 1442 8131 8166 9343 9375 10661 39707] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 4 5 22 33 47 48 50 52 61 62 63
66 71 75 76 77 78 86 89 90 91 92 93
95 99 103 104 105 106 107 108 114 115 117 118
119 120 121 122 124 127 128 129 130 131 132 133
134 135 137 142 143 144 145 146 147 152 153 154
155 156 157 158 159 160 161 162 163 164 165 167
168 169 170 171 172 173 174 518 538 539 580 685
962 1315 1337 1340 1493 1494 2136 2863 3491 3710 3711 4496
5036 5562 5623 5696 5697 6625 7206 7827 7877 7965 7987 8131
8203 8424 8468 8506 8842 8875 8947 8986 8988 9201 9243 9342
9343 9374 9375 9377 9411 10040 10100 10204 10246 10384 10402 10417
10424 10447 10496 10625 10626 10657 10661 10694 10733 10770 10809 10811
11428 11521 11532 11604 11694 11710 11725 11792 11850 11935 12915 12938
12950 13045 13058 13114 13281 13427 13622 13791 13831 13942 13993 14012
14049 14151 14200 14284 14406 14524 14600 14764 14844 14929 14962 15722
15835 15943 16025 16087 16096 16713 16932 17080 17087 17103 17125 17127
17149 17206 17236 17261 17268 17290 17403 17405 17464 17638 17641 17676
18051 18157 18269 18465 18540 18559 18615 18630 18669 18677 18782 18846
19203 19593 19732 19868 19897 20364 20849 20933 20935 20952 20986 21022
21182 21207 21261 21290 21357 21358 21366 21379 21398 21417 21432 21460
21864 22066 22236 22648 22699 22700 22723 22744 22810 22815 22818 22846
22861 23243 23246 23322 23573 23848 24000 24076 24191 24192 24221 24655
24658 24697 25145 25215 25305 25488 25528 25558 25574 25578 25580 25586
25631 25766 25798 26064 26065 26105 26145 26314 26773 26914 26941 26947
26964 27111 27290 27292 27293 27586 27622 27661 27841 28118 28214 28345
28395 28490 28491 28526 28527 28528 28565 28959 29117 29450 29723 29725
29758 29793 29829 30276 30525 30830 30837 30886 30944 30979 31019 31312
31320 31585 31616 32006 32116 32127 32183 32218 32439 32525 32804 33349
33745 33864 34024 34084 34738 35135 35912 35999 36511 36666 36799 36854
37041 37198 37261 37315 37782 37995 38055 38169 38314 38338 38563 38603
38637 38641 38690 38754 38867 38883 39008 39134 39156 39168 39214 39303
39339 39405 39490 39491 39517 39534 39704 39723 39832 39833 39845 39846
39858 39859 39860 39887] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [32088] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 20 71 77 93 152 163 169 518 580 664 705
723 724 948 962 1113 1317 1493 1494 1510 1990 2864 3710
3711 3726 5424 5487 5560 5696 5697 6178 7401 7815 7920 9198
9800 10097 10191 11399 11799 12154 12678 12891 12938 13045 13902 13993
14025 14049 14918 15284 15327 15587 15739 16520 17290 18118 18157 18465
18578 18782 19447 19593 19628 19629 19891 20933 20952 21022 21261 21433
23573 23938 24618 24658 24697 24736 25182 25798 25992 26064 26145 27111
27619 27626 27661 27932 28238 28394 28959 29117 29765 29792 29829 30276
31021 31057 31195 31232 31499 32116 32117 32156 32158 32192 32227 32594
33254 33294 33324 33745 34738 36278 36932 37070 37226 37315 37385 37620
37995 38208 38520 38521 38690 38827 38867 39054 39168 39481] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [6140] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 13 152 163 169 1442 8131 8166 9343 9375 10661 39707] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 4 5 22 33 47 48 50 52 61 62 63
66 71 75 76 77 78 86 89 90 91 92 93
95 99 103 104 105 106 107 108 114 115 117 118
119 120 121 122 124 127 128 129 130 131 132 133
134 135 137 142 143 144 145 146 147 152 153 154
155 156 157 158 159 160 161 162 163 164 165 167
168 169 170 171 172 173 174 518 538 539 580 685
962 1315 1337 1340 1493 1494 2136 2863 3491 3710 3711 4496
5036 5562 5623 5696 5697 6625 7206 7827 7877 7965 7987 8131
8203 8424 8468 8506 8842 8875 8947 8986 8988 9201 9243 9342
9343 9374 9375 9377 9411 10040 10100 10204 10246 10384 10402 10417
10424 10447 10496 10625 10626 10657 10661 10694 10733 10770 10809 10811
11428 11521 11532 11604 11694 11710 11725 11792 11850 11935 12915 12938
12950 13045 13058 13114 13281 13427 13622 13791 13831 13942 13993 14012
14049 14151 14200 14284 14406 14524 14600 14764 14844 14929 14962 15722
15835 15943 16025 16087 16096 16713 16932 17080 17087 17103 17125 17127
17149 17206 17236 17261 17268 17290 17403 17405 17464 17638 17641 17676
18051 18157 18269 18465 18540 18559 18615 18630 18669 18677 18782 18846
19203 19593 19732 19868 19897 20364 20849 20933 20935 20952 20986 21022
21182 21207 21261 21290 21357 21358 21366 21379 21398 21417 21432 21460
21864 22066 22236 22648 22699 22700 22723 22744 22810 22815 22818 22846
22861 23243 23246 23322 23573 23848 24000 24076 24191 24192 24221 24655
24658 24697 25145 25215 25305 25488 25528 25558 25574 25578 25580 25586
25631 25766 25798 26064 26065 26105 26145 26314 26773 26914 26941 26947
26964 27111 27290 27292 27293 27586 27622 27661 27841 28118 28214 28345
28395 28490 28491 28526 28527 28528 28565 28959 29117 29450 29723 29725
29758 29793 29829 30276 30525 30830 30837 30886 30944 30979 31019 31312
31320 31585 31616 32006 32116 32127 32183 32218 32439 32525 32804 33349
33745 33864 34024 34084 34738 35135 35912 35999 36511 36666 36799 36854
37041 37198 37261 37315 37782 37995 38055 38169 38314 38338 38563 38603
38637 38641 38690 38754 38867 38883 39008 39134 39156 39168 39214 39303
39339 39405 39490 39491 39517 39534 39704 39723 39832 39833 39845 39846
39858 39859 39860 39887] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [32088] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
Average validation scores by screening percentile:
screening_percentile=2: 0.5476
screening_percentile=4: 0.5999 (best)
screening_percentile=8: 0.5895
screening_percentile=16: 0.5669
screening_percentile=32: 0.4854
screening_percentile=64: 0.4736
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 152 163 169 1493 1494 3710 3711 5696 7987 9201 9343 10661
13045 13993 14049 14151 14764 16713 17087 18157 18782 20933 20952 21207
23573 25798 26105 26145 27111 27619 28959 30276 32127 32525 33745 34738
36511 37198 37315 37995 38867] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 52 99 152 162 169 172 173 174 255 294 511
512 518 537 538 539 540 557 580 644 664 705 724
726 743 744 818 819 927 931 948 969 1295 1317 1476
1492 1494 1513 1959 1990 1991 2006 2007 2027 2097 2143 2797
2851 2861 2863 2864 2865 2866 2983 3709 3710 3816 4679 4831
5046 5711 5894 6821 6989 9315 10490 12866 13805 14371 15739 16059
17156 17165 19604 21227 21252 27932 27961 30674 31646 31762 32679 35093
35204 36184 36545 36826 37620 38006 38202 38208 38255 38315 38340 38487
38501 38523 38722 38745 38867 38925 39095 39213 39444 39481 39517 39558
39635 39699 39716 39730] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [7875] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 6482 15078] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 152 162 169 172 173 174 238 538 580 2006 8099 8131
9343 9375 10661 12866 25589 38972 39584 39694] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [487 515 534 561 574 595 596 637 658 660 680 782 800 801 802 817 818 819
820 821 834 835 836 837 838 839 852 853 862 865] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [4579] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 4 5 13 22 50 52 58 59 60 61 62 63
66 67 68 69 70 71 72 73 74 75 76 77
78 79 80 81 82 83 84 85 86 87 88 89
90 91 92 93 94 95 96 97 98 99 100 101
102 103 104 105 106 107 108 109 110 111 112 113
114 115 116 117 118 119 120 121 122 123 124 125
126 127 128 129 130 131 132 133 134 135 136 137
138 139 140 141 142 143 144 145 146 147 148 149
150 151 152 153 154 155 156 157 158 159 160 161
162 163 164 165 166 167 168 169 170 171 172 173
174 538 539 580 9347 9375 10661 14697 16094 27961 35093 39192
39213 39444 39480 39699 39829 39830 39831 39832 39833 39841 39842 39843
39844 39845 39846 39854 39855 39856 39857 39858 39859 39860 39868 39869
39870 39879 39887] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 660 681 789 802 841 853 854 855 865 866 867 879
6140 7312 7348 7453 8536 8609 8643 13071 14298 14441 15834 22844
24199 26933 28244 29526 30127 38059] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 52 99 152 162 169 172 173 174 255 294 511
512 518 537 538 539 540 557 580 644 664 705 724
726 743 744 818 819 927 931 948 969 1295 1317 1476
1492 1494 1513 1959 1990 1991 2006 2007 2027 2097 2143 2797
2851 2861 2863 2864 2865 2866 2983 3709 3710 3816 4679 4831
5046 5711 5894 6821 6989 9315 10490 12866 13805 14371 15739 16059
17156 17165 19604 21227 21252 27932 27961 30674 31646 31762 32679 35093
35204 36184 36545 36826 37620 38006 38202 38208 38255 38315 38340 38487
38501 38523 38722 38745 38867 38925 39095 39213 39444 39481 39517 39558
39635 39699 39716 39730] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [7875] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 6482 15078] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 152 162 169 172 173 174 238 538 580 2006 8099 8131
9343 9375 10661 12866 25589 38972 39584 39694] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [487 515 534 561 574 595 596 637 658 660 680 782 800 801 802 817 818 819
820 821 834 835 836 837 838 839 852 853 862 865] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [4579] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 4 5 13 22 50 52 58 59 60 61 62 63
66 67 68 69 70 71 72 73 74 75 76 77
78 79 80 81 82 83 84 85 86 87 88 89
90 91 92 93 94 95 96 97 98 99 100 101
102 103 104 105 106 107 108 109 110 111 112 113
114 115 116 117 118 119 120 121 122 123 124 125
126 127 128 129 130 131 132 133 134 135 136 137
138 139 140 141 142 143 144 145 146 147 148 149
150 151 152 153 154 155 156 157 158 159 160 161
162 163 164 165 166 167 168 169 170 171 172 173
174 538 539 580 9347 9375 10661 14697 16094 27961 35093 39192
39213 39444 39480 39699 39829 39830 39831 39832 39833 39841 39842 39843
39844 39845 39846 39854 39855 39856 39857 39858 39859 39860 39868 39869
39870 39879 39887] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 660 681 789 802 841 853 854 855 865 866 867 879
6140 7312 7348 7453 8536 8609 8643 13071 14298 14441 15834 22844
24199 26933 28244 29526 30127 38059] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 52 99 152 162 169 172 173 174 255 294 511
512 518 537 538 539 540 557 580 644 664 705 724
726 743 744 818 819 927 931 948 969 1295 1317 1476
1492 1494 1513 1959 1990 1991 2006 2007 2027 2097 2143 2797
2851 2861 2863 2864 2865 2866 2983 3709 3710 3816 4679 4831
5046 5711 5894 6821 6989 9315 10490 12866 13805 14371 15739 16059
17156 17165 19604 21227 21252 27932 27961 30674 31646 31762 32679 35093
35204 36184 36545 36826 37620 38006 38202 38208 38255 38315 38340 38487
38501 38523 38722 38745 38867 38925 39095 39213 39444 39481 39517 39558
39635 39699 39716 39730] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [7875] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 6482 15078] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 152 162 169 172 173 174 238 538 580 2006 8099 8131
9343 9375 10661 12866 25589 38972 39584 39694] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [487 515 534 561 574 595 596 637 658 660 680 782 800 801 802 817 818 819
820 821 834 835 836 837 838 839 852 853 862 865] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [4579] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 4 5 13 22 50 52 58 59 60 61 62 63
66 67 68 69 70 71 72 73 74 75 76 77
78 79 80 81 82 83 84 85 86 87 88 89
90 91 92 93 94 95 96 97 98 99 100 101
102 103 104 105 106 107 108 109 110 111 112 113
114 115 116 117 118 119 120 121 122 123 124 125
126 127 128 129 130 131 132 133 134 135 136 137
138 139 140 141 142 143 144 145 146 147 148 149
150 151 152 153 154 155 156 157 158 159 160 161
162 163 164 165 166 167 168 169 170 171 172 173
174 538 539 580 9347 9375 10661 14697 16094 27961 35093 39192
39213 39444 39480 39699 39829 39830 39831 39832 39833 39841 39842 39843
39844 39845 39846 39854 39855 39856 39857 39858 39859 39860 39868 39869
39870 39879 39887] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 660 681 789 802 841 853 854 855 865 866 867 879
6140 7312 7348 7453 8536 8609 8643 13071 14298 14441 15834 22844
24199 26933 28244 29526 30127 38059] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 52 99 152 162 169 172 173 174 255 294 511
512 518 537 538 539 540 557 580 644 664 705 724
726 743 744 818 819 927 931 948 969 1295 1317 1476
1492 1494 1513 1959 1990 1991 2006 2007 2027 2097 2143 2797
2851 2861 2863 2864 2865 2866 2983 3709 3710 3816 4679 4831
5046 5711 5894 6821 6989 9315 10490 12866 13805 14371 15739 16059
17156 17165 19604 21227 21252 27932 27961 30674 31646 31762 32679 35093
35204 36184 36545 36826 37620 38006 38202 38208 38255 38315 38340 38487
38501 38523 38722 38745 38867 38925 39095 39213 39444 39481 39517 39558
39635 39699 39716 39730] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [7875] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 6482 15078] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 152 162 169 172 173 174 238 538 580 2006 8099 8131
9343 9375 10661 12866 25589 38972 39584 39694] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [487 515 534 561 574 595 596 637 658 660 680 782 800 801 802 817 818 819
820 821 834 835 836 837 838 839 852 853 862 865] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [4579] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 4 5 13 22 50 52 58 59 60 61 62 63
66 67 68 69 70 71 72 73 74 75 76 77
78 79 80 81 82 83 84 85 86 87 88 89
90 91 92 93 94 95 96 97 98 99 100 101
102 103 104 105 106 107 108 109 110 111 112 113
114 115 116 117 118 119 120 121 122 123 124 125
126 127 128 129 130 131 132 133 134 135 136 137
138 139 140 141 142 143 144 145 146 147 148 149
150 151 152 153 154 155 156 157 158 159 160 161
162 163 164 165 166 167 168 169 170 171 172 173
174 538 539 580 9347 9375 10661 14697 16094 27961 35093 39192
39213 39444 39480 39699 39829 39830 39831 39832 39833 39841 39842 39843
39844 39845 39846 39854 39855 39856 39857 39858 39859 39860 39868 39869
39870 39879 39887] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 660 681 789 802 841 853 854 855 865 866 867 879
6140 7312 7348 7453 8536 8609 8643 13071 14298 14441 15834 22844
24199 26933 28244 29526 30127 38059] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 52 99 152 162 169 172 173 174 255 294 511
512 518 537 538 539 540 557 580 644 664 705 724
726 743 744 818 819 927 931 948 969 1295 1317 1476
1492 1494 1513 1959 1990 1991 2006 2007 2027 2097 2143 2797
2851 2861 2863 2864 2865 2866 2983 3709 3710 3816 4679 4831
5046 5711 5894 6821 6989 9315 10490 12866 13805 14371 15739 16059
17156 17165 19604 21227 21252 27932 27961 30674 31646 31762 32679 35093
35204 36184 36545 36826 37620 38006 38202 38208 38255 38315 38340 38487
38501 38523 38722 38745 38867 38925 39095 39213 39444 39481 39517 39558
39635 39699 39716 39730] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [7875] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 6482 15078] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 152 162 169 172 173 174 238 538 580 2006 8099 8131
9343 9375 10661 12866 25589 38972 39584 39694] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [487 515 534 561 574 595 596 637 658 660 680 782 800 801 802 817 818 819
820 821 834 835 836 837 838 839 852 853 862 865] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [4579] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 4 5 13 22 50 52 58 59 60 61 62 63
66 67 68 69 70 71 72 73 74 75 76 77
78 79 80 81 82 83 84 85 86 87 88 89
90 91 92 93 94 95 96 97 98 99 100 101
102 103 104 105 106 107 108 109 110 111 112 113
114 115 116 117 118 119 120 121 122 123 124 125
126 127 128 129 130 131 132 133 134 135 136 137
138 139 140 141 142 143 144 145 146 147 148 149
150 151 152 153 154 155 156 157 158 159 160 161
162 163 164 165 166 167 168 169 170 171 172 173
174 538 539 580 9347 9375 10661 14697 16094 27961 35093 39192
39213 39444 39480 39699 39829 39830 39831 39832 39833 39841 39842 39843
39844 39845 39846 39854 39855 39856 39857 39858 39859 39860 39868 39869
39870 39879 39887] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 660 681 789 802 841 853 854 855 865 866 867 879
6140 7312 7348 7453 8536 8609 8643 13071 14298 14441 15834 22844
24199 26933 28244 29526 30127 38059] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 3 52 99 152 162 169 172 173 174 255 294 511
512 518 537 538 539 540 557 580 644 664 705 724
726 743 744 818 819 927 931 948 969 1295 1317 1476
1492 1494 1513 1959 1990 1991 2006 2007 2027 2097 2143 2797
2851 2861 2863 2864 2865 2866 2983 3709 3710 3816 4679 4831
5046 5711 5894 6821 6989 9315 10490 12866 13805 14371 15739 16059
17156 17165 19604 21227 21252 27932 27961 30674 31646 31762 32679 35093
35204 36184 36545 36826 37620 38006 38202 38208 38255 38315 38340 38487
38501 38523 38722 38745 38867 38925 39095 39213 39444 39481 39517 39558
39635 39699 39716 39730] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [7875] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 6482 15078] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 152 162 169 172 173 174 238 538 580 2006 8099 8131
9343 9375 10661 12866 25589 38972 39584 39694] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [487 515 534 561 574 595 596 637 658 660 680 782 800 801 802 817 818 819
820 821 834 835 836 837 838 839 852 853 862 865] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [4579] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 4 5 13 22 50 52 58 59 60 61 62 63
66 67 68 69 70 71 72 73 74 75 76 77
78 79 80 81 82 83 84 85 86 87 88 89
90 91 92 93 94 95 96 97 98 99 100 101
102 103 104 105 106 107 108 109 110 111 112 113
114 115 116 117 118 119 120 121 122 123 124 125
126 127 128 129 130 131 132 133 134 135 136 137
138 139 140 141 142 143 144 145 146 147 148 149
150 151 152 153 154 155 156 157 158 159 160 161
162 163 164 165 166 167 168 169 170 171 172 173
174 538 539 580 9347 9375 10661 14697 16094 27961 35093 39192
39213 39444 39480 39699 39829 39830 39831 39832 39833 39841 39842 39843
39844 39845 39846 39854 39855 39856 39857 39858 39859 39860 39868 39869
39870 39879 39887] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 660 681 789 802 841 853 854 855 865 866 867 879
6140 7312 7348 7453 8536 8609 8643 13071 14298 14441 15834 22844
24199 26933 28244 29526 30127 38059] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
Average validation scores by screening percentile:
screening_percentile=2: 0.5601
screening_percentile=4: 0.5629
screening_percentile=8: 0.5657
screening_percentile=16: 0.5766
screening_percentile=32: 0.5781
screening_percentile=64: 0.5822 (best)
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 22 95 99 152 162 169 172 173 174 538 539 557
580 1494 2006 10661 12866 27961 38208 39213] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning:
Features [ 660 865 6140 7312] are constant.
/home/runner/work/nilearn/nilearn/.tox/doc/lib/python3.10/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning:
invalid value encountered in divide
Mean ± std test score: 0.7029 ± 0.0693
Total running time of the script: (1 minutes 8.653 seconds)
Estimated memory usage: 1053 MB