Note
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
Second-level fMRI model: one sample test¶
Full step-by-step example of fitting a GLM to perform a second-level analysis (one-sample test) and visualizing the results.
More specifically:
A sequence of subject fMRI button press contrasts is downloaded.
A mask of the useful brain volume is computed.
A one-sample t-test is applied to the brain maps.
We focus on a given contrast of the localizer dataset: the motor response to left versus right button press. Both at the individual and group level, this is expected to elicit activity in the motor cortex (positive in the right hemisphere, negative in the left hemisphere).
from nilearn import plotting
Fetch dataset¶
We download a list of left vs right button press contrasts from a localizer dataset. Note that we fetch individual t-maps that represent the BOLD activity estimate divided by the uncertainty about this estimate.
from nilearn.datasets import fetch_localizer_contrasts
n_subjects = 16
data = fetch_localizer_contrasts(
["left vs right button press"],
n_subjects,
get_tmaps=True,
)
[fetch_localizer_contrasts] Dataset directory found:
/home/runner/nilearn_data/brainomics_localizer
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d27cb281c5b4a001aa07e29/ ...
[fetch_localizer_contrasts] ...done. (3 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d27ca3d1c5b4a001b9eeddb/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d27e787114a420016059c22/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d27eba2114a420016059fbf/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d27efab1c5b4a001aa0a0c2/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d27f296114a42001704a5d9/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d28095545253a001c3e59a2/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d280608a26b3400180868d1/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d28144c114a42001804739e/ ...
[fetch_localizer_contrasts] ...done. (3 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d2811d0114a42001704b988/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d281e3d114a42001605cb02/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d281f851c5b4a001b9f2315/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d28375345253a001c3e90a2/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d282d9045253a001c3e80a1/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d283f021c5b4a001aa100cb/ ...
[fetch_localizer_contrasts] ...done. (3 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d283ee0a26b34001609f58e/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d2852caa26b340018089ae5/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d285263114a4200160602c6/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d28660b1c5b4a001aa122c7/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d285d61114a42001904a343/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d2868f9114a42001704f6a5/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d28709e114a420016061aa1/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d28847d114a42001904b87b/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d287b3a45253a00193d145e/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d289736114a4200170518d7/ ...
[fetch_localizer_contrasts] ...done. (3 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d28966345253a00193d2e27/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d28b135a26b3400160a648e/ ...
[fetch_localizer_contrasts] ...done. (3 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d28a431a26b340019090fa2/ ...
[fetch_localizer_contrasts] ...done. (3 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d28c0a81c5b4a001b9fb89a/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
[fetch_localizer_contrasts] Downloading data from
https://osf.io/download/5d28b761a26b3400160a6ba8/ ...
[fetch_localizer_contrasts] ...done. (2 seconds, 0 min)
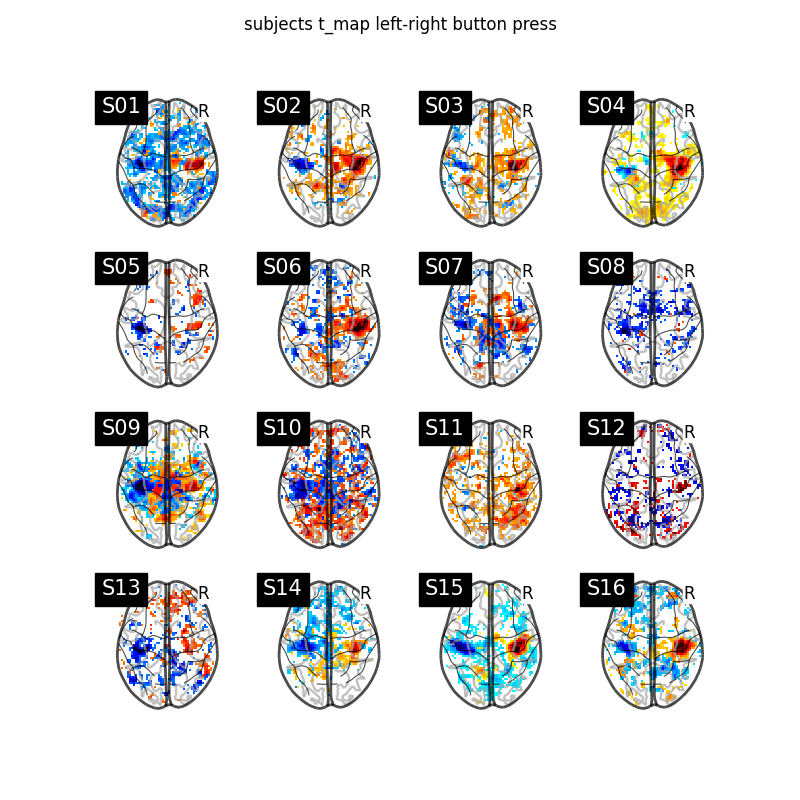
Display subject t_maps¶
We plot a grid with all the subjects t-maps thresholded at t = 2 for simple visualization purposes. The button press effect is visible among all subjects.
import matplotlib.pyplot as plt
subjects = data["ext_vars"]["participant_id"].tolist()
fig, axes = plt.subplots(nrows=4, ncols=4, figsize=(8, 8))
for cidx, tmap in enumerate(data["tmaps"]):
plotting.plot_glass_brain(
tmap,
colorbar=False,
threshold=2.0,
title=subjects[cidx],
axes=axes[int(cidx / 4), int(cidx % 4)],
plot_abs=False,
display_mode="z",
vmin=-8.5,
vmax=8.5,
)
fig.suptitle("subjects t_map left-right button press")
plt.show()
Estimate second level model¶
We wish to perform a one-sample test. In order to do so, we need to create a design matrix that determines how the analysis will be performed. For a one-sample test, all we need to include in the design matrix is a single column of ones, corresponding to the model intercept.
import pandas as pd
second_level_input = data["cmaps"]
design_matrix = pd.DataFrame(
[1] * len(second_level_input),
columns=["intercept"],
)
Next, we specify the model and fit it.
from nilearn.glm.second_level import SecondLevelModel
second_level_model = SecondLevelModel(smoothing_fwhm=8.0, n_jobs=2, verbose=1)
second_level_model = second_level_model.fit(
second_level_input,
design_matrix=design_matrix,
)
\[SecondLevelModel.fit] Fitting second level model. Take a deep breath.
\[SecondLevelModel.fit]
Computation of second level model done in 00 HR 00 MIN 00 SEC.
To estimate the contrast is very simple. We can just provide the column name of the design matrix.
z_map = second_level_model.compute_contrast(
second_level_contrast="intercept",
output_type="z_score",
)
We threshold the second level contrast at uncorrected p < 0.001 and plot it.
from scipy.stats import norm
p_val = 0.001
p001_unc = norm.isf(p_val)
display = plotting.plot_glass_brain(
z_map,
threshold=p001_unc,
display_mode="z",
plot_abs=False,
title="group left-right button press (unc p<0.001)",
figure=plt.figure(figsize=(5, 5)),
)
plotting.show()
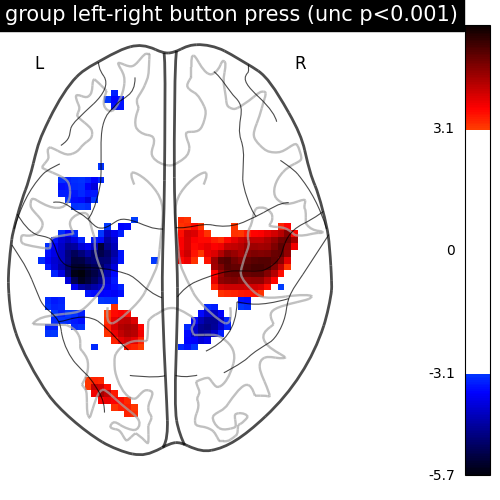
As expected, we find the motor cortex.
Next, we compute the (corrected) p-values with a parametric test to compare them with the results from a nonparametric test.
import numpy as np
from nilearn.image import get_data, math_img
p_val = second_level_model.compute_contrast(output_type="p_value")
n_voxels = np.sum(get_data(second_level_model.masker_.mask_img_))
# Correcting the p-values for multiple testing and taking negative logarithm
neg_log_pval = math_img(
f"-np.log10(np.minimum(1, img * {n_voxels!s}))",
img=p_val,
)
<string>:1: RuntimeWarning:
divide by zero encountered in log10
Now, we compute the (corrected) p-values with a permutation test.
We will use non_parametric_inference for
this step, although permuted_ols could be
used as well (pending additional steps to mask and reformat the inputs).
Important
One key difference between
SecondLevelModel and
non_parametric_inference/
permuted_ols
is that the one-sample test in non_parametric_inference/permuted_ols
assumes that the distribution is symmetric about 0,
which is weaker than the SecondLevelModel’s assumption that
the null distribution is Gaussian and centered about 0.
Important
In this example, threshold is set to 0.001, which enables
cluster-level inference.
Performing cluster-level inference will increase the computation time of
the permutation procedure.
Increasing the number of parallel jobs (n_jobs) can reduce the time
cost.
Hint
If you wish to only run voxel-level correction, set threshold to None
(the default).
from nilearn.glm.second_level import non_parametric_inference
out_dict = non_parametric_inference(
second_level_input,
design_matrix=design_matrix,
model_intercept=True,
n_perm=500, # 500 for the sake of time. Ideally, this should be 10,000.
two_sided_test=False,
smoothing_fwhm=8.0,
n_jobs=2,
threshold=0.001,
verbose=1,
)
[non_parametric_inference] Fitting second level model...
[non_parametric_inference]
Computation of second level model done in 00 HR 00 MIN 00 SEC
/home/runner/work/nilearn/nilearn/examples/05_glm_second_level/plot_second_level_one_sample_test.py:163: UserWarning:
Data array used to create a new image contains 64-bit ints. This is likely due to creating the array with numpy and passing `int` as the `dtype`. Many tools such as FSL and SPM cannot deal with int64 in Nifti images, so for compatibility the data has been converted to int32.
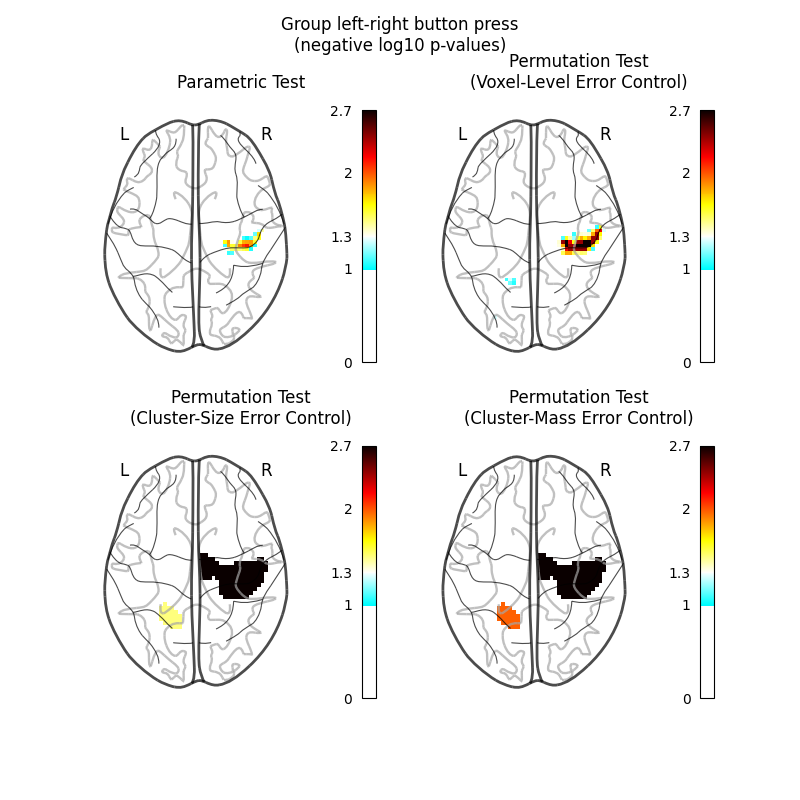
Let us plot the (corrected) negative log p-values for the both tests.
We will use a negative log10 p threshold of 1, which corresponds to p<0.1. This threshold indicates that there is less than 10% probability to make a single false discovery (90% chance that we make no false discovery at all). This threshold is much more conservative than an uncorrected threshold, but is still more liberal than a typical corrected threshold for this kind of analysis, which tends to be ~0.05.
We will also cap the negative log10 p-values at 2.69, because this is the maximum observable value for the nonparametric tests, which were run with only 500 permutations.
import itertools
threshold = 1 # p < 0.1
vmax = 2.69 # ~= -np.log10(1 / 500)
cut_coords = [0]
IMAGES = [
neg_log_pval,
out_dict["logp_max_t"],
out_dict["logp_max_size"],
out_dict["logp_max_mass"],
]
TITLES = [
"Parametric Test",
"Permutation Test\n(Voxel-Level Error Control)",
"Permutation Test\n(Cluster-Size Error Control)",
"Permutation Test\n(Cluster-Mass Error Control)",
]
fig, axes = plt.subplots(figsize=(8, 8), nrows=2, ncols=2)
for img_counter, (i_row, j_col) in enumerate(
itertools.product(range(2), range(2))
):
ax = axes[i_row, j_col]
plotting.plot_glass_brain(
IMAGES[img_counter],
vmax=vmax,
vmin=threshold,
display_mode="z",
plot_abs=False,
cut_coords=cut_coords,
threshold=threshold,
figure=fig,
axes=ax,
cmap="inferno",
)
ax.set_title(TITLES[img_counter])
fig.suptitle("Group left-right button press\n(negative log10 p-values)")
plt.show()
/home/runner/work/nilearn/nilearn/examples/05_glm_second_level/plot_second_level_one_sample_test.py:213: UserWarning:
Non-finite values detected. These values will be replaced with zeros.
The nonparametric test yields many more discoveries and is more powerful than the usual parametric procedure. Even within the nonparametric test, the different correction metrics produce different results. The voxel-level correction is more conservative than the cluster-size or cluster-mass corrections, which are very similar to one another.
Total running time of the script: (1 minutes 16.459 seconds)
Estimated memory usage: 145 MB