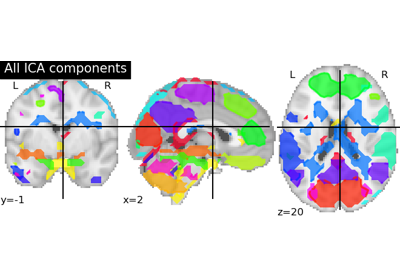
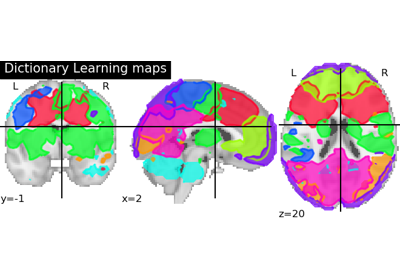
Note
This page is a reference documentation. It only explains the class signature, and not how to use it. Please refer to the user guide for the big picture.
8.4.2. nilearn.decomposition.DictLearning¶
- class
nilearn.decomposition.DictLearning(n_components=20, n_epochs=1, alpha=10, reduction_ratio='auto', dict_init=None, random_state=None, batch_size=20, method='cd', mask=None, smoothing_fwhm=4, standardize=True, detrend=True, low_pass=None, high_pass=None, t_r=None, target_affine=None, target_shape=None, mask_strategy='epi', mask_args=None, n_jobs=1, verbose=0, memory=Memory(location=None), memory_level=0)¶ Perform a map learning algorithm based on spatial component sparsity, over a CanICA initialization. This yields more stable maps than CanICA.
New in version 0.2.
Parameters: mask: Niimg-like object or MultiNiftiMasker instance, optional
Mask to be used on data. If an instance of masker is passed, then its mask will be used. If no mask is given, it will be computed automatically by a MultiNiftiMasker with default parameters.
n_components: int
Number of components to extract. By default n_components=20.
batch_size : int, optional, default=20
The number of samples to take in each batch.
n_epochs: float, default=1
Number of epochs the algorithm should run on the data.
alpha: float, optional, default=10
Sparsity controlling parameter.
dict_init: Niimg-like object, optional
Initial estimation of dictionary maps. Would be computed from CanICA if not provided.
reduction_ratio: ‘auto’ or float between 0. and 1.
- Between 0. or 1. : controls data reduction in the temporal domain. 1. means no reduction, < 1. calls for an SVD based reduction.
- if set to ‘auto’, estimator will set the number of components per reduced session to be n_components.
method : {‘lars’, ‘cd’}, default=’cd’
Coding method used by sklearn backend. Below are the possible values. lars: uses the least angle regression method to solve the lasso problem (linear_model.lars_path) cd: uses the coordinate descent method to compute the Lasso solution (linear_model.Lasso). Lars will be faster if the estimated components are sparse.
random_state: int or RandomState
Pseudo number generator state used for random sampling.
smoothing_fwhm: float, optional, default=4mm
If smoothing_fwhm is not None, it gives the size in millimeters of the spatial smoothing to apply to the signal.
standardize : boolean, optional, default=True
If standardize is True, the time-series are centered and normed: their variance is put to 1 in the time dimension.
detrend : boolean, optional, default=True
If detrend is True, the time-series will be detrended before components extraction.
target_affine: 3x3 or 4x4 matrix, optional
This parameter is passed to image.resample_img. Please see the related documentation for details.
target_shape: 3-tuple of integers, optional
This parameter is passed to image.resample_img. Please see the related documentation for details.
low_pass: None or float, optional
This parameter is passed to signal.clean. Please see the related documentation for details.
high_pass: None or float, optional
This parameter is passed to signal.clean. Please see the related documentation for details.
t_r: float, optional
This parameter is passed to signal.clean. Please see the related documentation for details.
mask_strategy: {‘background’, ‘epi’ or ‘template’}, optional
The strategy used to compute the mask: use ‘background’ if your images present a clear homogeneous background, ‘epi’ if they are raw EPI images, or you could use ‘template’ which will extract the gray matter part of your data by resampling the MNI152 brain mask for your data’s field of view. Depending on this value, the mask will be computed from masking.compute_background_mask, masking.compute_epi_mask or masking.compute_brain_mask. Default is ‘epi’.
mask_args: dict, optional
If mask is None, these are additional parameters passed to masking.compute_background_mask or masking.compute_epi_mask to fine-tune mask computation. Please see the related documentation for details.
memory: instance of joblib.Memory or string
Used to cache the masking process. By default, no caching is done. If a string is given, it is the path to the caching directory.
memory_level: integer, optional
Rough estimator of the amount of memory used by caching. Higher value means more memory for caching.
n_jobs: integer, optional, default=1
The number of CPUs to use to do the computation. -1 means ‘all CPUs’, -2 ‘all CPUs but one’, and so on.
verbose: integer, optional
Indicate the level of verbosity. By default, nothing is printed.
References
- Arthur Mensch, Gael Varoquaux, Bertrand Thirion, Compressed online dictionary learning for fast resting-state fMRI decomposition. IEEE 13th International Symposium on Biomedical Imaging (ISBI), 2016. pp. 1282-1285
Attributes
`components_` (2D numpy array (n_components x n-voxels)) Masked dictionary components extracted from the input images. Deprecated since version 0.4.1. Use components_img_ instead `components_img_` (4D Nifti image) 4D image giving the extracted components. Each 3D image is a component. New in version 0.4.1. `masker_` (instance of MultiNiftiMasker) Masker used to filter and mask data as first step. If an instance of MultiNiftiMasker is given in mask parameter, this is a copy of it. Otherwise, a masker is created using the value of mask and other NiftiMasker related parameters as initialization. `mask_img_` (Niimg-like object) See http://nilearn.github.io/manipulating_images/input_output.html The mask of the data. If no mask was given at masker creation, contains the automatically computed mask. __init__(n_components=20, n_epochs=1, alpha=10, reduction_ratio='auto', dict_init=None, random_state=None, batch_size=20, method='cd', mask=None, smoothing_fwhm=4, standardize=True, detrend=True, low_pass=None, high_pass=None, t_r=None, target_affine=None, target_shape=None, mask_strategy='epi', mask_args=None, n_jobs=1, verbose=0, memory=Memory(location=None), memory_level=0)¶Initialize self. See help(type(self)) for accurate signature.
fit(imgs, y=None, confounds=None)¶Compute the mask and the components across subjects
Parameters: imgs: list of Niimg-like objects
See http://nilearn.github.io/manipulating_images/input_output.html Data on which the mask is calculated. If this is a list, the affine is considered the same for all.
confounds : list of CSV file paths or numpy.ndarrays or pandas DataFrames, optional,
This parameter is passed to nilearn.signal.clean. Please see the related documentation for details. Should match with the list of imgs given.
Returns: self : object
Returns the instance itself. Contains attributes listed at the object level.
fit_transform(X, y=None, **fit_params)¶Fit to data, then transform it.
Fits transformer to X and y with optional parameters fit_params and returns a transformed version of X.
Parameters: X : {array-like, sparse matrix, dataframe} of shape (n_samples, n_features)
Input samples.
y : ndarray of shape (n_samples,), default=None
Target values (None for unsupervised transformations).
**fit_params : dict
Additional fit parameters.
Returns: X_new : ndarray array of shape (n_samples, n_features_new)
Transformed array.
get_params(deep=True)¶Get parameters for this estimator.
Parameters: deep : bool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
Returns: params : mapping of string to any
Parameter names mapped to their values.
inverse_transform(loadings)¶Use provided loadings to compute corresponding linear component combination in whole-brain voxel space
Parameters: loadings: list of numpy array (n_samples x n_components)
Component signals to tranform back into voxel signals
Returns: reconstructed_imgs: list of nibabel.Nifti1Image
For each loading, reconstructed Nifti1Image
score(imgs, confounds=None, per_component=False)¶Score function based on explained variance on imgs.
Should only be used by DecompositionEstimator derived classes
Parameters: imgs: iterable of Niimg-like objects
See http://nilearn.github.io/manipulating_images/input_output.html Data to be scored
confounds: CSV file path or numpy.ndarray or pandas DataFrame, optional,
This parameter is passed to nilearn.signal.clean. Please see the related documentation for details
per_component: bool, default False
Specify whether the explained variance ratio is desired for each map or for the global set of components
Returns: score: float,
Holds the score for each subjects. Score is two dimensional if per_component is True. First dimension is squeezed if the number of subjects is one
set_params(**params)¶Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form
<component>__<parameter>so that it’s possible to update each component of a nested object.Parameters: **params : dict
Estimator parameters.
Returns: self : object
Estimator instance.
transform(imgs, confounds=None)¶Project the data into a reduced representation
Parameters: imgs: iterable of Niimg-like objects
See http://nilearn.github.io/manipulating_images/input_output.html Data to be projected
confounds: CSV file path or numpy.ndarray or pandas DataFrame, optional,
This parameter is passed to nilearn.signal.clean. Please see the related documentation for details
Returns: loadings: list of 2D ndarray,
For each subject, each sample, loadings for each decomposition components shape: number of subjects * (number of scans, number of regions)