Note
Go to the end to download the full example code or to run this example in your browser via Binder
BIDS dataset first and second level analysis#
Full step-by-step example of fitting a GLM to perform a first and second level analysis in a BIDS dataset and visualizing the results. Details about the BIDS standard can be consulted at http://bids.neuroimaging.io/.
More specifically:
Download an fMRI BIDS dataset with two language conditions to contrast.
Extract first level model objects automatically from the BIDS dataset.
Fit a second level model on the fitted first level models. Notice that in this case the preprocessed bold images were already normalized to the same MNI space.
Fetch example BIDS dataset#
We download a simplified BIDS dataset made available for illustrative purposes. It contains only the necessary information to run a statistical analysis using Nilearn. The raw data subject folders only contain bold.json and events.tsv files, while the derivatives folder includes the preprocessed files preproc.nii and the confounds.tsv files.
from nilearn.datasets import fetch_language_localizer_demo_dataset
data_dir, _ = fetch_language_localizer_demo_dataset()
Dataset created in /home/remi/nilearn_data/fMRI-language-localizer-demo-dataset
Downloading data from https://osf.io/3dj2a/download ...
Downloaded 4268032 of 749503182 bytes (0.6%, 2.9min remaining)
Downloaded 9846784 of 749503182 bytes (1.3%, 2.5min remaining)
Downloaded 15532032 of 749503182 bytes (2.1%, 2.4min remaining)
Downloaded 23887872 of 749503182 bytes (3.2%, 2.1min remaining)
Downloaded 31604736 of 749503182 bytes (4.2%, 1.9min remaining)
Downloaded 38174720 of 749503182 bytes (5.1%, 1.9min remaining)
Downloaded 45924352 of 749503182 bytes (6.1%, 1.8min remaining)
Downloaded 53493760 of 749503182 bytes (7.1%, 1.8min remaining)
Downloaded 61079552 of 749503182 bytes (8.1%, 1.7min remaining)
Downloaded 68657152 of 749503182 bytes (9.2%, 1.7min remaining)
Downloaded 75530240 of 749503182 bytes (10.1%, 1.7min remaining)
Downloaded 83279872 of 749503182 bytes (11.1%, 1.6min remaining)
Downloaded 90849280 of 749503182 bytes (12.1%, 1.6min remaining)
Downloaded 98631680 of 749503182 bytes (13.2%, 1.6min remaining)
Downloaded 106266624 of 749503182 bytes (14.2%, 1.5min remaining)
Downloaded 112820224 of 749503182 bytes (15.1%, 1.5min remaining)
Downloaded 120225792 of 749503182 bytes (16.0%, 1.5min remaining)
Downloaded 128253952 of 749503182 bytes (17.1%, 1.5min remaining)
Downloaded 136511488 of 749503182 bytes (18.2%, 1.4min remaining)
Downloaded 144539648 of 749503182 bytes (19.3%, 1.4min remaining)
Downloaded 151191552 of 749503182 bytes (20.2%, 1.4min remaining)
Downloaded 158941184 of 749503182 bytes (21.2%, 1.4min remaining)
Downloaded 166592512 of 749503182 bytes (22.2%, 1.3min remaining)
Downloaded 174505984 of 749503182 bytes (23.3%, 1.3min remaining)
Downloaded 182009856 of 749503182 bytes (24.3%, 1.3min remaining)
Downloaded 189431808 of 749503182 bytes (25.3%, 1.3min remaining)
Downloaded 196329472 of 749503182 bytes (26.2%, 1.3min remaining)
Downloaded 203915264 of 749503182 bytes (27.2%, 1.3min remaining)
Downloaded 211566592 of 749503182 bytes (28.2%, 1.2min remaining)
Downloaded 219037696 of 749503182 bytes (29.2%, 1.2min remaining)
Downloaded 226500608 of 749503182 bytes (30.2%, 1.2min remaining)
Downloaded 233144320 of 749503182 bytes (31.1%, 1.2min remaining)
Downloaded 240762880 of 749503182 bytes (32.1%, 1.2min remaining)
Downloaded 248086528 of 749503182 bytes (33.1%, 1.2min remaining)
Downloaded 255442944 of 749503182 bytes (34.1%, 1.1min remaining)
Downloaded 262897664 of 749503182 bytes (35.1%, 1.1min remaining)
Downloaded 269680640 of 749503182 bytes (36.0%, 1.1min remaining)
Downloaded 277495808 of 749503182 bytes (37.0%, 1.1min remaining)
Downloaded 285310976 of 749503182 bytes (38.1%, 1.1min remaining)
Downloaded 293076992 of 749503182 bytes (39.1%, 1.0min remaining)
Downloaded 300908544 of 749503182 bytes (40.1%, 1.0min remaining)
Downloaded 307445760 of 749503182 bytes (41.0%, 1.0min remaining)
Downloaded 315179008 of 749503182 bytes (42.1%, 59.5s remaining)
Downloaded 323010560 of 749503182 bytes (43.1%, 58.3s remaining)
Downloaded 330792960 of 749503182 bytes (44.1%, 57.2s remaining)
Downloaded 338681856 of 749503182 bytes (45.2%, 56.0s remaining)
Downloaded 346406912 of 749503182 bytes (46.2%, 54.9s remaining)
Downloaded 353435648 of 749503182 bytes (47.2%, 54.0s remaining)
Downloaded 361398272 of 749503182 bytes (48.2%, 52.8s remaining)
Downloaded 369016832 of 749503182 bytes (49.2%, 51.7s remaining)
Downloaded 376979456 of 749503182 bytes (50.3%, 50.6s remaining)
Downloaded 384892928 of 749503182 bytes (51.4%, 49.4s remaining)
Downloaded 391626752 of 749503182 bytes (52.3%, 48.6s remaining)
Downloaded 400048128 of 749503182 bytes (53.4%, 47.3s remaining)
Downloaded 407961600 of 749503182 bytes (54.4%, 46.2s remaining)
Downloaded 415842304 of 749503182 bytes (55.5%, 45.1s remaining)
Downloaded 423690240 of 749503182 bytes (56.5%, 44.0s remaining)
Downloaded 430571520 of 749503182 bytes (57.4%, 43.1s remaining)
Downloaded 438534144 of 749503182 bytes (58.5%, 42.0s remaining)
Downloaded 446767104 of 749503182 bytes (59.6%, 40.8s remaining)
Downloaded 455049216 of 749503182 bytes (60.7%, 39.6s remaining)
Downloaded 462454784 of 749503182 bytes (61.7%, 38.6s remaining)
Downloaded 468631552 of 749503182 bytes (62.5%, 37.9s remaining)
Downloaded 476250112 of 749503182 bytes (63.5%, 36.8s remaining)
Downloaded 483844096 of 749503182 bytes (64.6%, 35.8s remaining)
Downloaded 491749376 of 749503182 bytes (65.6%, 34.7s remaining)
Downloaded 500121600 of 749503182 bytes (66.7%, 33.5s remaining)
Downloaded 508477440 of 749503182 bytes (67.8%, 32.3s remaining)
Downloaded 515555328 of 749503182 bytes (68.8%, 31.4s remaining)
Downloaded 523714560 of 749503182 bytes (69.9%, 30.3s remaining)
Downloaded 532185088 of 749503182 bytes (71.0%, 29.1s remaining)
Downloaded 540614656 of 749503182 bytes (72.1%, 27.9s remaining)
Downloaded 548421632 of 749503182 bytes (73.2%, 26.9s remaining)
Downloaded 555237376 of 749503182 bytes (74.1%, 26.0s remaining)
Downloaded 563331072 of 749503182 bytes (75.2%, 24.9s remaining)
Downloaded 571064320 of 749503182 bytes (76.2%, 23.8s remaining)
Downloaded 579567616 of 749503182 bytes (77.3%, 22.6s remaining)
Downloaded 587710464 of 749503182 bytes (78.4%, 21.5s remaining)
Downloaded 594755584 of 749503182 bytes (79.4%, 20.6s remaining)
Downloaded 602800128 of 749503182 bytes (80.4%, 19.5s remaining)
Downloaded 610942976 of 749503182 bytes (81.5%, 18.4s remaining)
Downloaded 618938368 of 749503182 bytes (82.6%, 17.3s remaining)
Downloaded 626982912 of 749503182 bytes (83.7%, 16.3s remaining)
Downloaded 633372672 of 749503182 bytes (84.5%, 15.4s remaining)
Downloaded 641171456 of 749503182 bytes (85.5%, 14.4s remaining)
Downloaded 649019392 of 749503182 bytes (86.6%, 13.4s remaining)
Downloaded 657014784 of 749503182 bytes (87.7%, 12.3s remaining)
Downloaded 665108480 of 749503182 bytes (88.7%, 11.2s remaining)
Downloaded 673185792 of 749503182 bytes (89.8%, 10.1s remaining)
Downloaded 680574976 of 749503182 bytes (90.8%, 9.1s remaining)
Downloaded 688373760 of 749503182 bytes (91.8%, 8.1s remaining)
Downloaded 696434688 of 749503182 bytes (92.9%, 7.0s remaining)
Downloaded 704593920 of 749503182 bytes (94.0%, 5.9s remaining)
Downloaded 712556544 of 749503182 bytes (95.1%, 4.9s remaining)
Downloaded 719650816 of 749503182 bytes (96.0%, 4.0s remaining)
Downloaded 726589440 of 749503182 bytes (96.9%, 3.0s remaining)
Downloaded 735854592 of 749503182 bytes (98.2%, 1.8s remaining)
Downloaded 743817216 of 749503182 bytes (99.2%, 0.8s remaining) ...done. (101 seconds, 1 min)
Extracting data from /home/remi/nilearn_data/fMRI-language-localizer-demo-dataset/fMRI-language-localizer-demo-dataset.zip..... done.
Here is the location of the dataset on disk.
print(data_dir)
/home/remi/nilearn_data/fMRI-language-localizer-demo-dataset
Obtain automatically FirstLevelModel objects and fit arguments#
From the dataset directory we automatically obtain the FirstLevelModel objects with their subject_id filled from the BIDS dataset. Moreover, we obtain for each model a dictionary with run_imgs, events and confounder regressors since in this case a confounds.tsv file is available in the BIDS dataset. To get the first level models we only have to specify the dataset directory and the task_label as specified in the file names.
from nilearn.glm.first_level import first_level_from_bids
task_label = "languagelocalizer"
(
models,
models_run_imgs,
models_events,
models_confounds,
) = first_level_from_bids(
data_dir, task_label, img_filters=[("desc", "preproc")]
)
/home/remi/github/nilearn/env/lib/python3.11/site-packages/nilearn/interfaces/bids/query.py:49: UserWarning:
'StartTime' not found in file /home/remi/nilearn_data/fMRI-language-localizer-demo-dataset/derivatives/sub-01/func/sub-01_task-languagelocalizer_desc-preproc_bold.json.
Quick sanity check on fit arguments#
Additional checks or information extraction from pre-processed data can be made here.
We just expect one run_img per subject.
import os
print([os.path.basename(run) for run in models_run_imgs[0]])
['sub-05_task-languagelocalizer_desc-preproc_bold.nii.gz']
The only confounds stored are regressors obtained from motion correction. As we can verify from the column headers of the confounds table corresponding to the only run_img present.
print(models_confounds[0][0].columns)
Index(['RotX', 'RotY', 'RotZ', 'X', 'Y', 'Z'], dtype='object')
During this acquisition the subject read blocks of sentences and consonant strings. So these are our only two conditions in events. We verify there are 12 blocks for each condition.
print(models_events[0][0]["trial_type"].value_counts())
trial_type
language 12
string 12
Name: count, dtype: int64
First level model estimation#
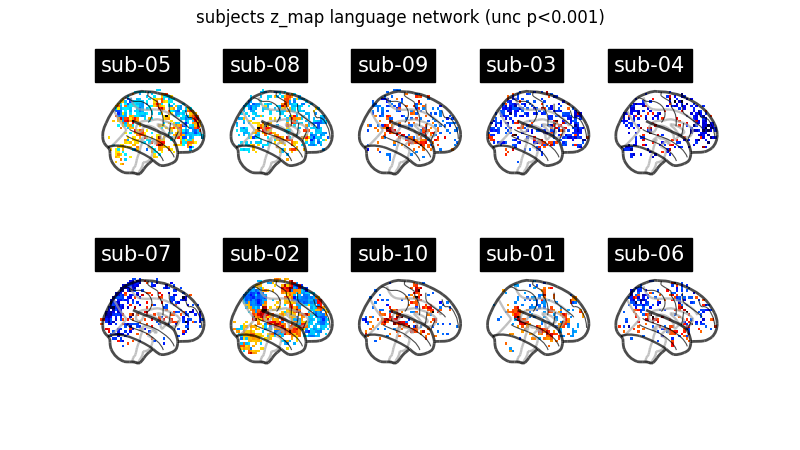
Now we simply fit each first level model and plot for each subject the contrast that reveals the language network (language - string). Notice that we can define a contrast using the names of the conditions specified in the events dataframe. Sum, subtraction and scalar multiplication are allowed.
Set the threshold as the z-variate with an uncorrected p-value of 0.001.
Prepare figure for concurrent plot of individual maps.
import matplotlib.pyplot as plt
from nilearn import plotting
fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(8, 4.5))
model_and_args = zip(models, models_run_imgs, models_events, models_confounds)
for midx, (model, imgs, events, confounds) in enumerate(model_and_args):
# fit the GLM
model.fit(imgs, events, confounds)
# compute the contrast of interest
zmap = model.compute_contrast("language-string")
plotting.plot_glass_brain(
zmap,
colorbar=False,
threshold=p001_unc,
title=f"sub-{model.subject_label}",
axes=axes[int(midx / 5), int(midx % 5)],
plot_abs=False,
display_mode="x",
)
fig.suptitle("subjects z_map language network (unc p<0.001)")
plotting.show()
Second level model estimation#
We just have to provide the list of fitted FirstLevelModel objects to the SecondLevelModel object for estimation. We can do this because all subjects share a similar design matrix (same variables reflected in column names).
from nilearn.glm.second_level import SecondLevelModel
second_level_input = models
Note that we apply a smoothing of 8mm.
second_level_model = SecondLevelModel(smoothing_fwhm=8.0)
second_level_model = second_level_model.fit(second_level_input)
Computing contrasts at the second level is as simple as at the first level. Since we are not providing confounders we are performing a one-sample test at the second level with the images determined by the specified first level contrast.
zmap = second_level_model.compute_contrast(
first_level_contrast="language-string"
)
The group level contrast reveals a left lateralized fronto-temporal language network.
plotting.plot_glass_brain(
zmap,
colorbar=True,
threshold=p001_unc,
title="Group language network (unc p<0.001)",
plot_abs=False,
display_mode="x",
figure=plt.figure(figsize=(5, 4)),
)
plotting.show()

Total running time of the script: (2 minutes 30.539 seconds)
Estimated memory usage: 188 MB