Note
Click here to download the full example code or to run this example in your browser via Binder
Example of generic design in second-level models#
This example shows the results obtained in a group analysis using a more complex contrast than a one- or two-sample t test. We use the [left button press (auditory cue)] task from the Localizer dataset and seek association between the contrast values and a variate that measures the speed of pseudo-word reading. No confounding variate is included in the model.
# Author: Virgile Fritsch, Bertrand Thirion, 2014 -- 2018
# Jerome-Alexis Chevalier, 2019
At first, we need to load the Localizer contrasts.
from nilearn import datasets
n_samples = 94
localizer_dataset = datasets.fetch_localizer_contrasts(
['left button press (auditory cue)'],
n_subjects=n_samples, legacy_format=False
)
Let’s print basic information on the dataset.
print('First contrast nifti image (3D) is located at: %s' %
localizer_dataset.cmaps[0])
First contrast nifti image (3D) is located at: /home/yasmin/nilearn/nilearn_data/brainomics_localizer/brainomics_data/S01/cmaps_LeftAuditoryClick.nii.gz
we also need to load the behavioral variable.
tested_var = localizer_dataset.ext_vars['pseudo']
print(tested_var)
0 15.0
1 16.0
2 14.0
3 19.0
4 16.0
...
89 12.0
90 16.0
91 13.0
92 25.0
93 21.0
Name: pseudo, Length: 94, dtype: float64
It is worth to do a auality check and remove subjects with missing values.
import numpy as np
mask_quality_check = np.where(
np.logical_not(np.isnan(tested_var))
)[0]
n_samples = mask_quality_check.size
contrast_map_filenames = [localizer_dataset.cmaps[i]
for i in mask_quality_check]
tested_var = tested_var[mask_quality_check].values.reshape((-1, 1))
print("Actual number of subjects after quality check: %d" % n_samples)
Actual number of subjects after quality check: 89
Estimate second level model#
We define the input maps and the design matrix for the second level model and fit it.
import pandas as pd
design_matrix = pd.DataFrame(
np.hstack((tested_var, np.ones_like(tested_var))),
columns=['fluency', 'intercept'])
Fit of the second-level model
from nilearn.glm.second_level import SecondLevelModel
model = SecondLevelModel(smoothing_fwhm=5.0)
model.fit(contrast_map_filenames, design_matrix=design_matrix)
To estimate the contrast is very simple. We can just provide the column name of the design matrix.
z_map = model.compute_contrast('fluency', output_type='z_score')
We compute the fdr-corrected p = 0.05 threshold for these data
from nilearn.glm import threshold_stats_img
_, threshold = threshold_stats_img(z_map, alpha=.05, height_control='fdr')
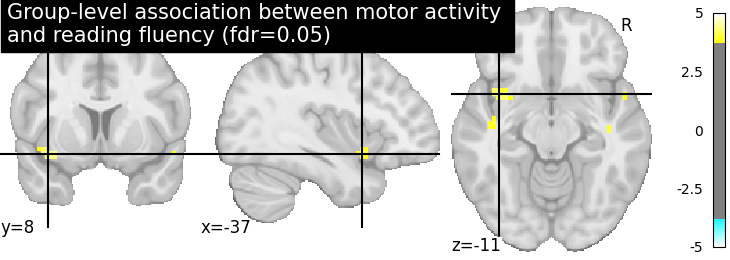
Let us plot the second level contrast at the computed thresholds
from nilearn import plotting
plotting.plot_stat_map(
z_map, threshold=threshold, colorbar=True,
title='Group-level association between motor activity \n'
'and reading fluency (fdr=0.05)')
plotting.show()
Computing the (corrected) p-values with parametric test to compare with non parametric test
from nilearn.image import math_img
from nilearn.image import get_data
p_val = model.compute_contrast('fluency', output_type='p_value')
n_voxels = np.sum(get_data(model.masker_.mask_img_))
# Correcting the p-values for multiple testing and taking negative logarithm
neg_log_pval = math_img("-np.log10(np.minimum(1, img * {}))"
.format(str(n_voxels)),
img=p_val)
<string>:1: RuntimeWarning:
divide by zero encountered in log10
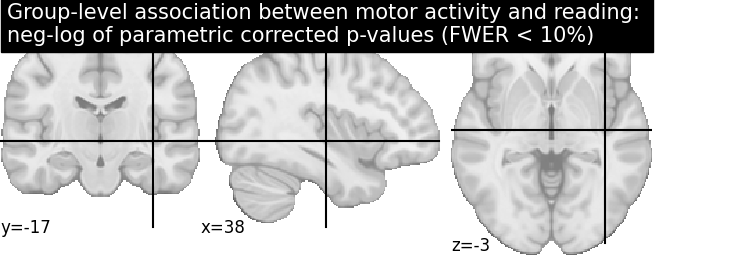
Let us plot the (corrected) negative log p-values for the parametric test
cut_coords = [38, -17, -3]
# Since we are plotting negative log p-values and using a threshold equal to 1,
# it corresponds to corrected p-values lower than 10%, meaning that there
# is less than 10% probability to make a single false discovery
# (90% chance that we make no false discoveries at all).
# This threshold is much more conservative than the previous one.
threshold = 1
title = ('Group-level association between motor activity and reading: \n'
'neg-log of parametric corrected p-values (FWER < 10%)')
plotting.plot_stat_map(neg_log_pval, colorbar=True, cut_coords=cut_coords,
threshold=threshold, title=title)
plotting.show()
/home/yasmin/nilearn/nilearn/nilearn/_utils/niimg.py:63: UserWarning:
Non-finite values detected. These values will be replaced with zeros.
Computing the (corrected) negative log p-values with permutation test
from nilearn.glm.second_level import non_parametric_inference
neg_log_pvals_permuted_ols_unmasked = \
non_parametric_inference(contrast_map_filenames,
design_matrix=design_matrix,
second_level_contrast='fluency',
model_intercept=True, n_perm=1000,
two_sided_test=False, mask=None,
smoothing_fwhm=5.0, n_jobs=1)
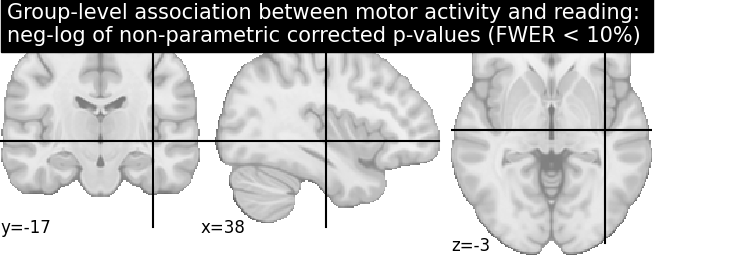
Let us plot the (corrected) negative log p-values
title = ('Group-level association between motor activity and reading: \n'
'neg-log of non-parametric corrected p-values (FWER < 10%)')
plotting.plot_stat_map(neg_log_pvals_permuted_ols_unmasked, colorbar=True,
cut_coords=cut_coords, threshold=threshold,
title=title)
plotting.show()
# The neg-log p-values obtained with non parametric testing are capped at 3
# since the number of permutations is 1e3.
# The non parametric test yields a few more discoveries
# and is then more powerful than the usual parametric procedure.
Total running time of the script: ( 1 minutes 28.124 seconds)
Estimated memory usage: 153 MB